In the rapidly evolving landscape of large language models (LLMs), the ability to access and synthesize vast amounts of information is paramount. While LLMs excel at generating creative text and understanding complex prompts, their knowledge is often limited to the data used during their training. This is where knowledge bases (a.k.a. retrieval-augmented generation, or RAG) come into play, providing a dynamic and expandable repository of information that can significantly augment an LLM's capabilities, particularly in specialized domains such as cybersecurity.
This blog post will guide you through the process of leveraging Open WebUI knowledge bases to enable your LLMs to intelligently query and retrieve information from your custom cybersecurity content. This system will keep your content confidential locally, on your computer, rather than sending it to the cloud, as with ChatGPT and Deepseek. Whether you're looking to build a sophisticated Q&A system for threat intelligence, enhance incident response with specific factual details from security reports, or simply make your LLMs more informed about the latest vulnerabilities and attack vectors, integrating a knowledge base is a crucial step. We'll walk through the setup process and demonstrate how to effectively use this powerful combination to unlock a new level of intelligence and critical cybersecurity insights.
Begin by installing Ollama on your system. Here is the GitHub link with installation instructions. For this blog, I downloaded and installed the base model by executing “ollama pull qwen3:14b.”
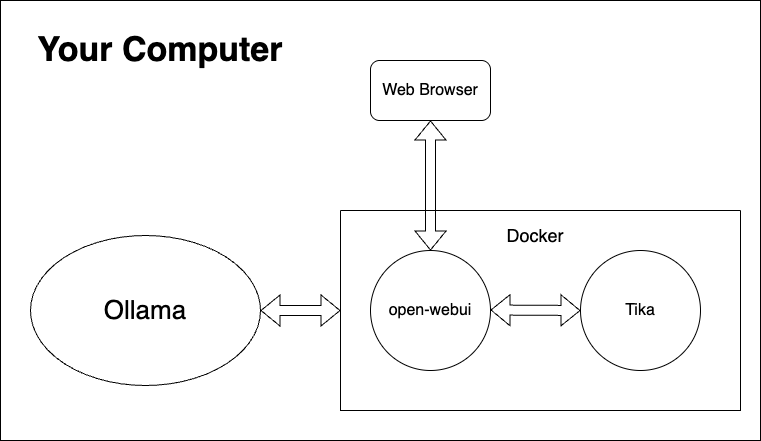
Next, I've provided a Docker Compose file here to launch Open WebUI and Apache Tika servers. Docker, as shown in the diagram below, allows you to run containers (virtual servers) with installed software so that you do not have to worry about the complexities of installing them on your computer. Here, Apache Tika is essential for extracting content from various file types, including using OCR to retrieve text from PDFs for Open WebUI.
The Docker compose file is:
Put the Docker compose file above in a directory, name it docker-compose.yml, and run it with Docker using the following command:
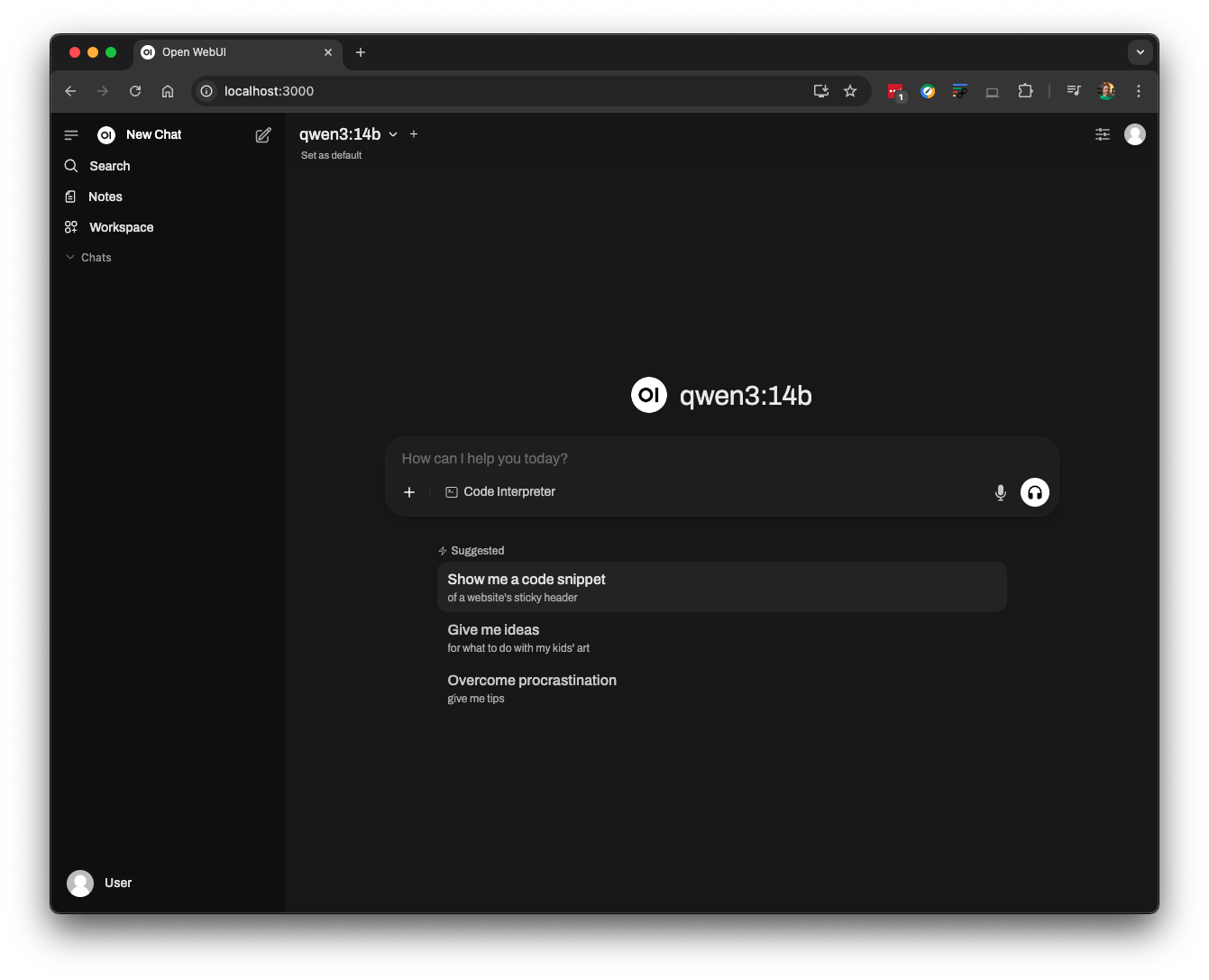
Once running, you can then open your web browser and visit http://localhost:3000 to get the Open WebUI welcome screen:
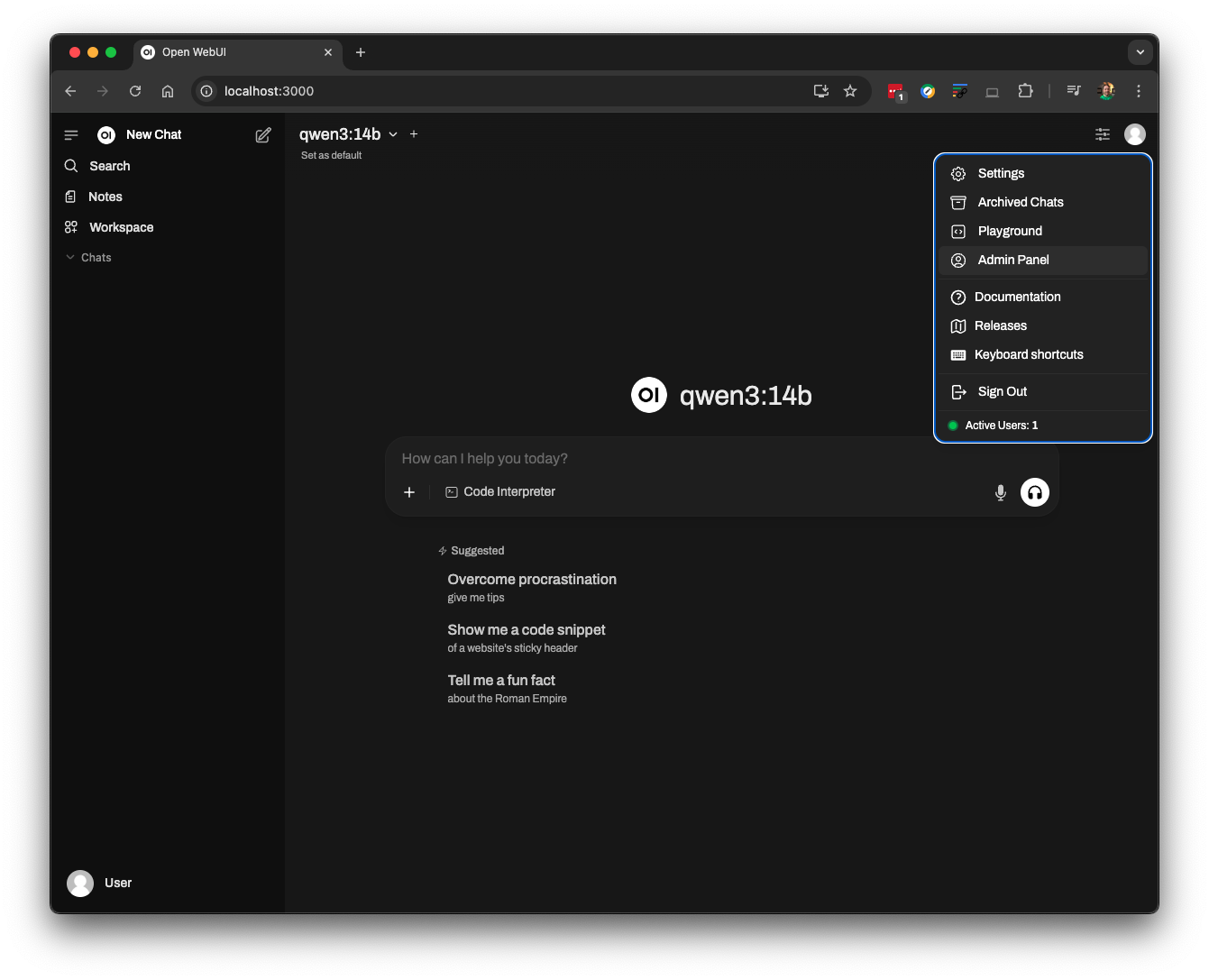
The first thing you need to do is configure Open WebUI. Open the Admin Panel using the icon in the upper right corner:
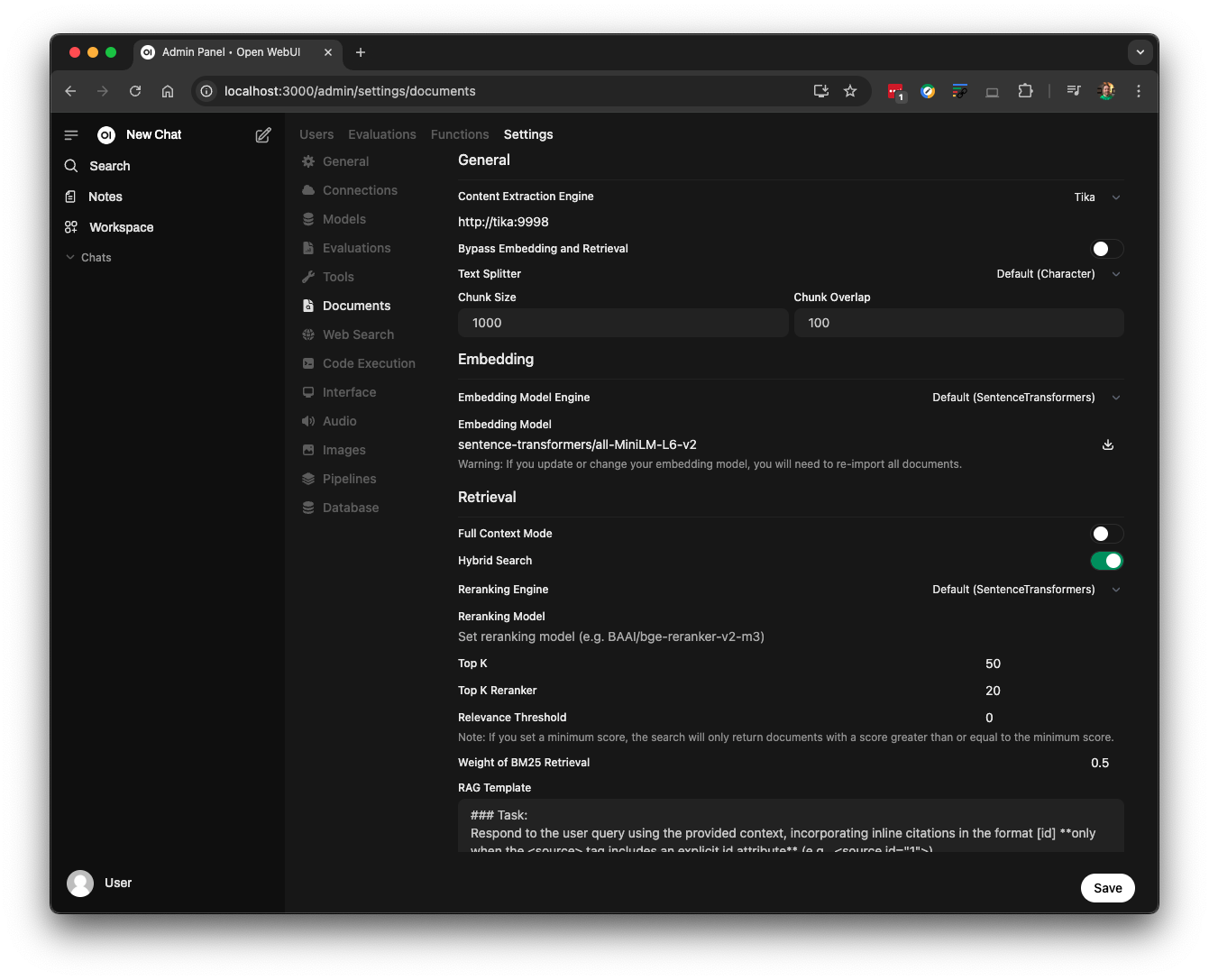
… and from there navigate to Settings -> Documents. Change the Content Extraction Engine to Tika, enable Hybrid Search, set Top K to 50, and Top K Reranker to 20 like I did:
If your system has limited memory, you can decrease the values for Top K and Top K Reranker. The current settings are optimized for my Apple laptop, which has 32 GB of GPU RAM.
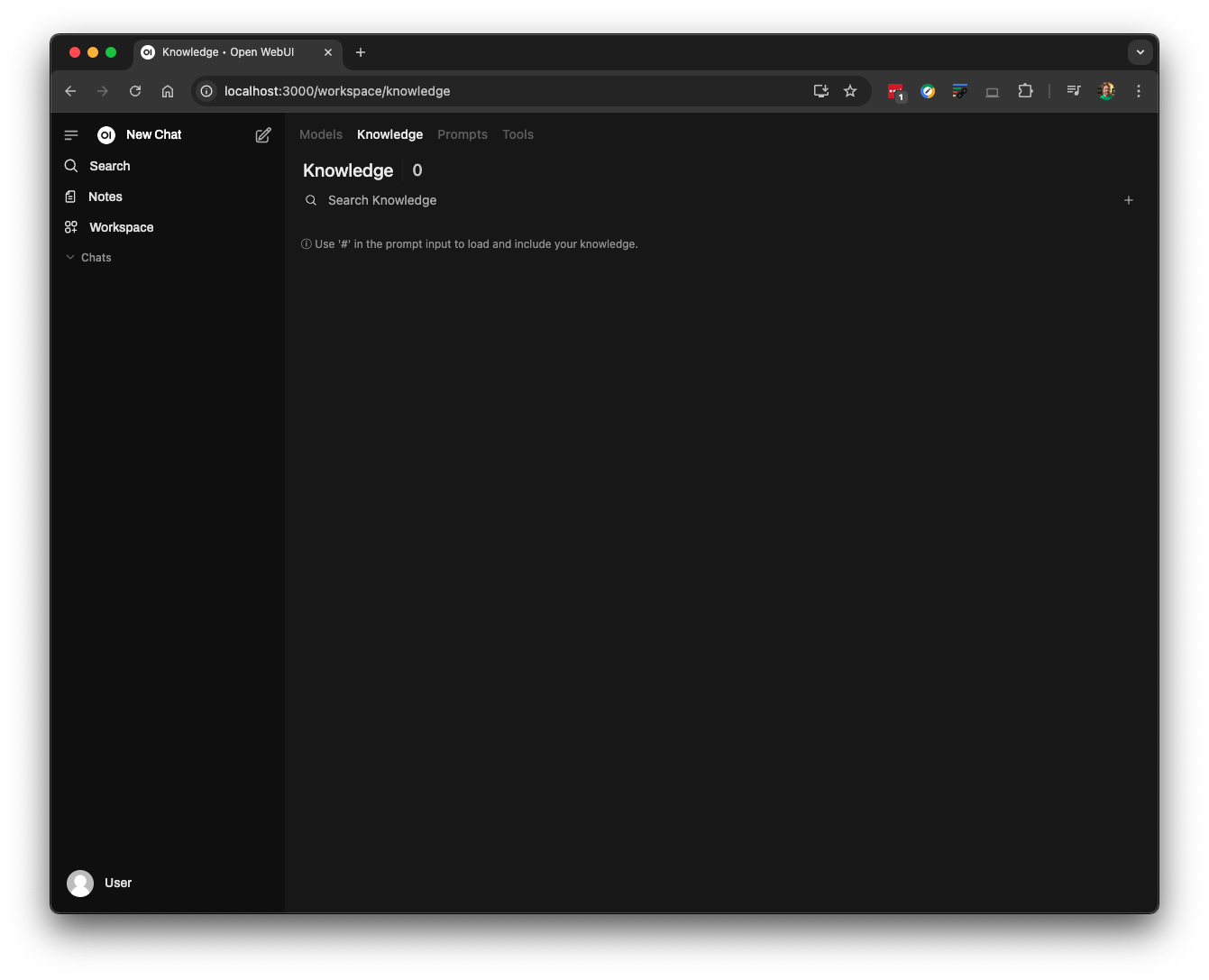
To begin creating your knowledge base, navigate to "Workspace" in the left column, then select "Knowledge" at the top. This will display a screen indicating that no knowledge bases have been created yet.
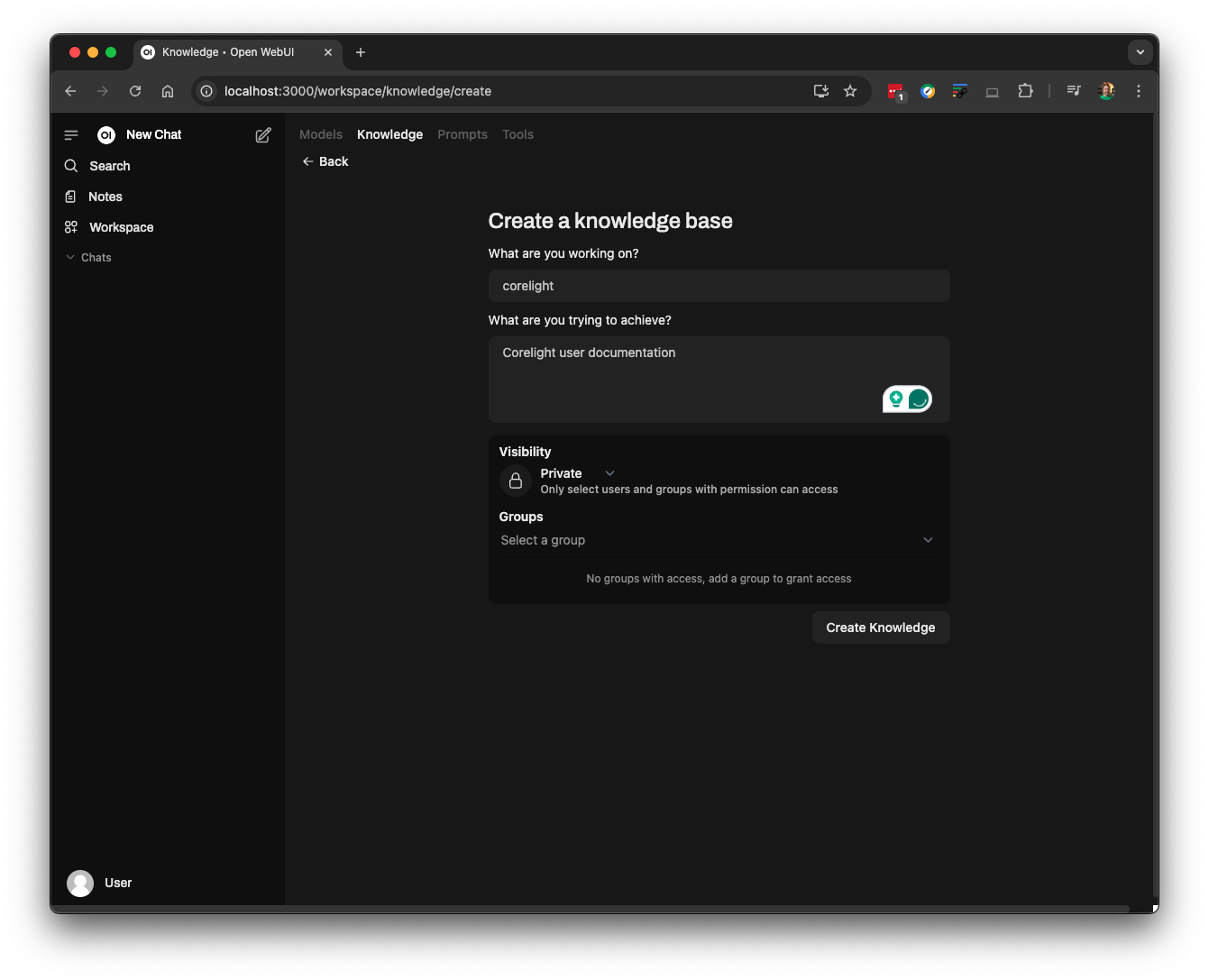
Create a knowledge base by clicking the plus sign. Here I am creating a knowledge base called “corelight” for some PDF documentation:
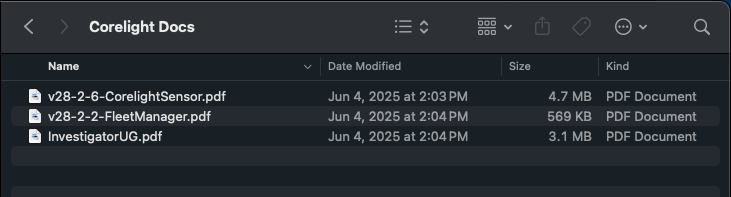
There are three Corelight user documents available to customers as PDFs, and when combined, the files are about 1,000 pages of content. If you do not have access to these documents, experiment with the PDFs you have access to, or you can participate in the “Analyzing Zeek®’s AgentTesla Malware Detector” section below to analyze an open-source, publicly available Zeek package. The three files are:
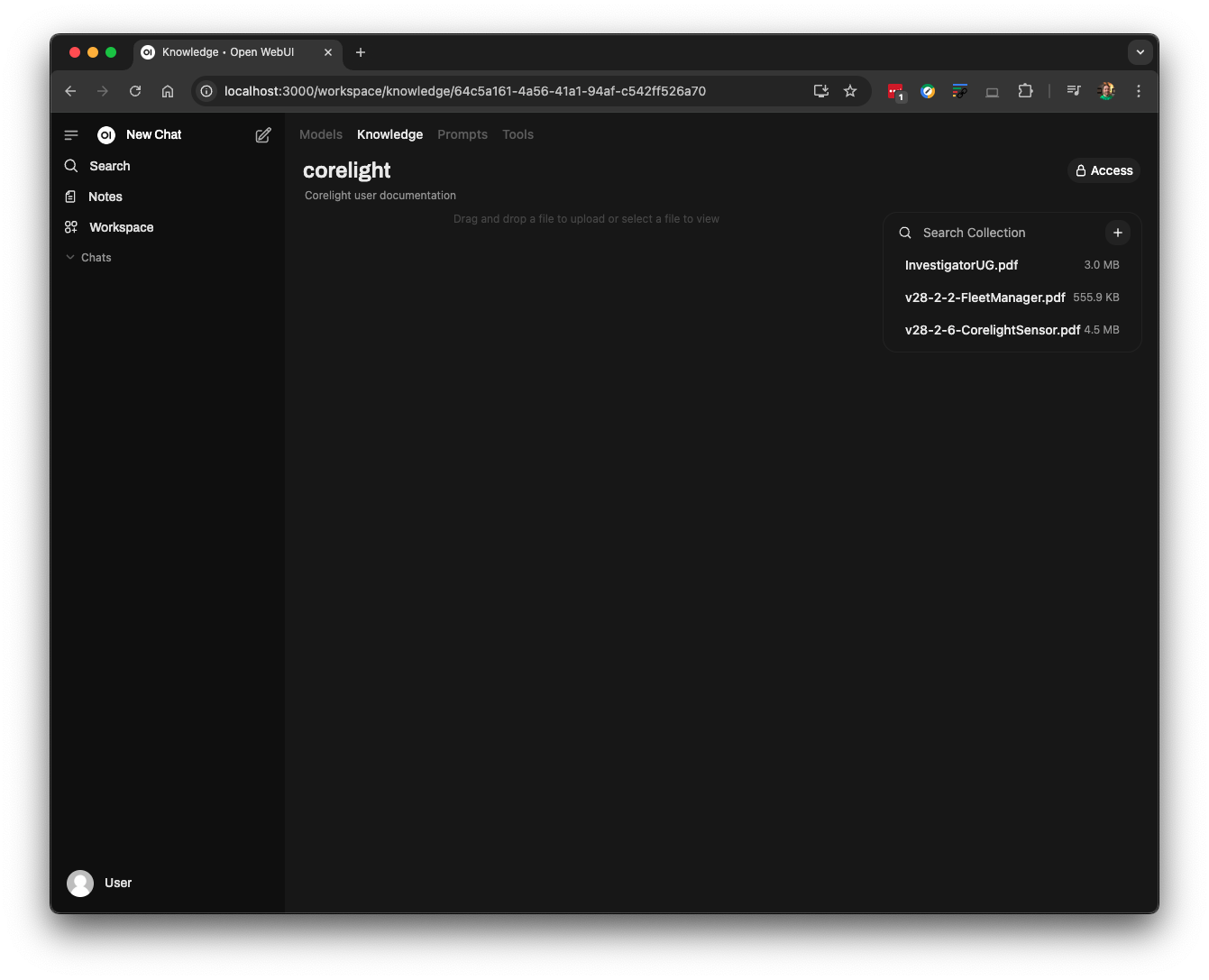
We can drag and drop these three files into our knowledge base:
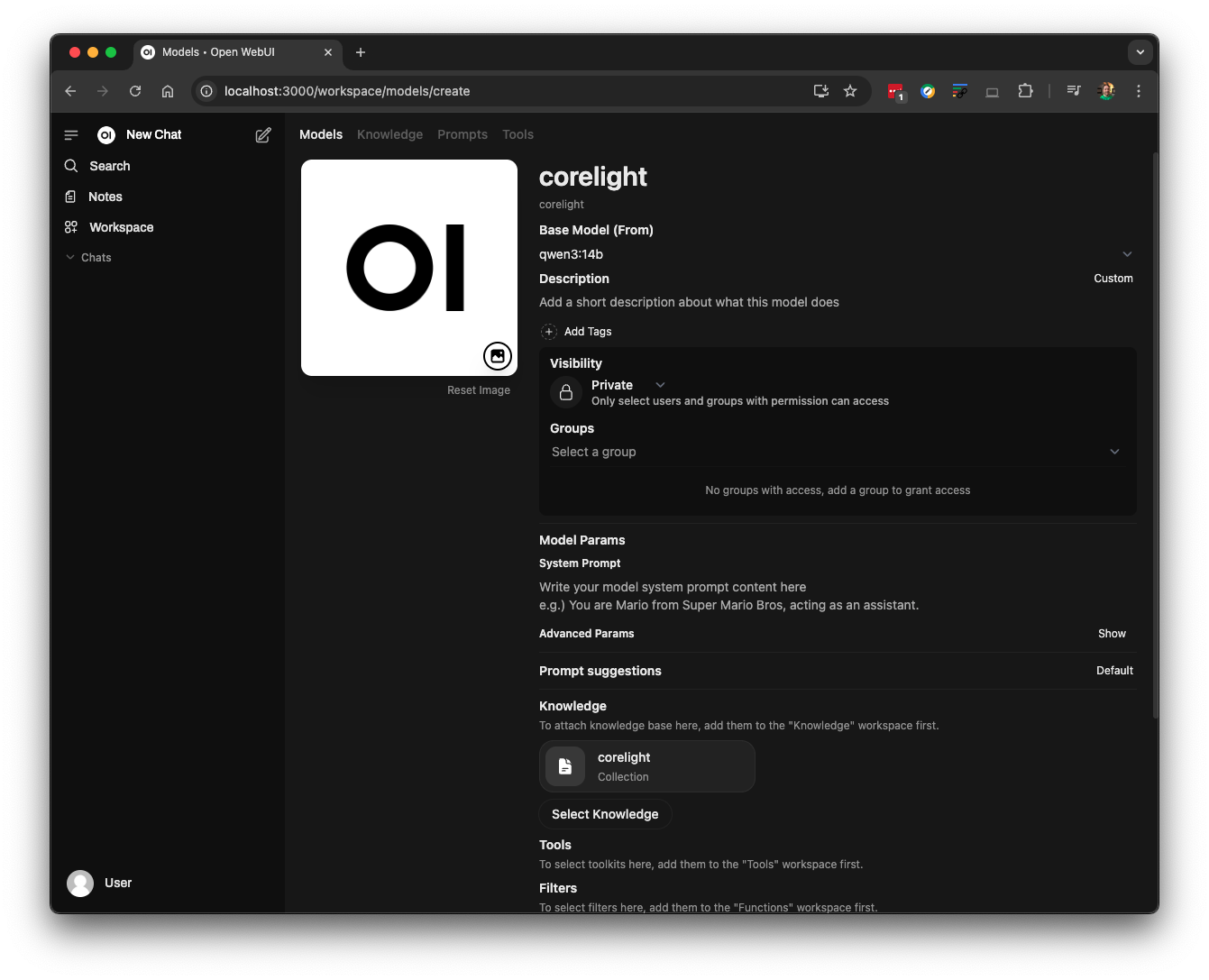
Next, we will create a custom model based on “qwen3:14b” and attach it to our knowledge base. This will allow for easier querying later. To begin, navigate to Workspace -> Model.
I'll name this model "corelight" and use "qwen3:14b" as its base model. The "corelight" knowledge base will be automatically linked to this model by selecting it from the Knowledge menu.
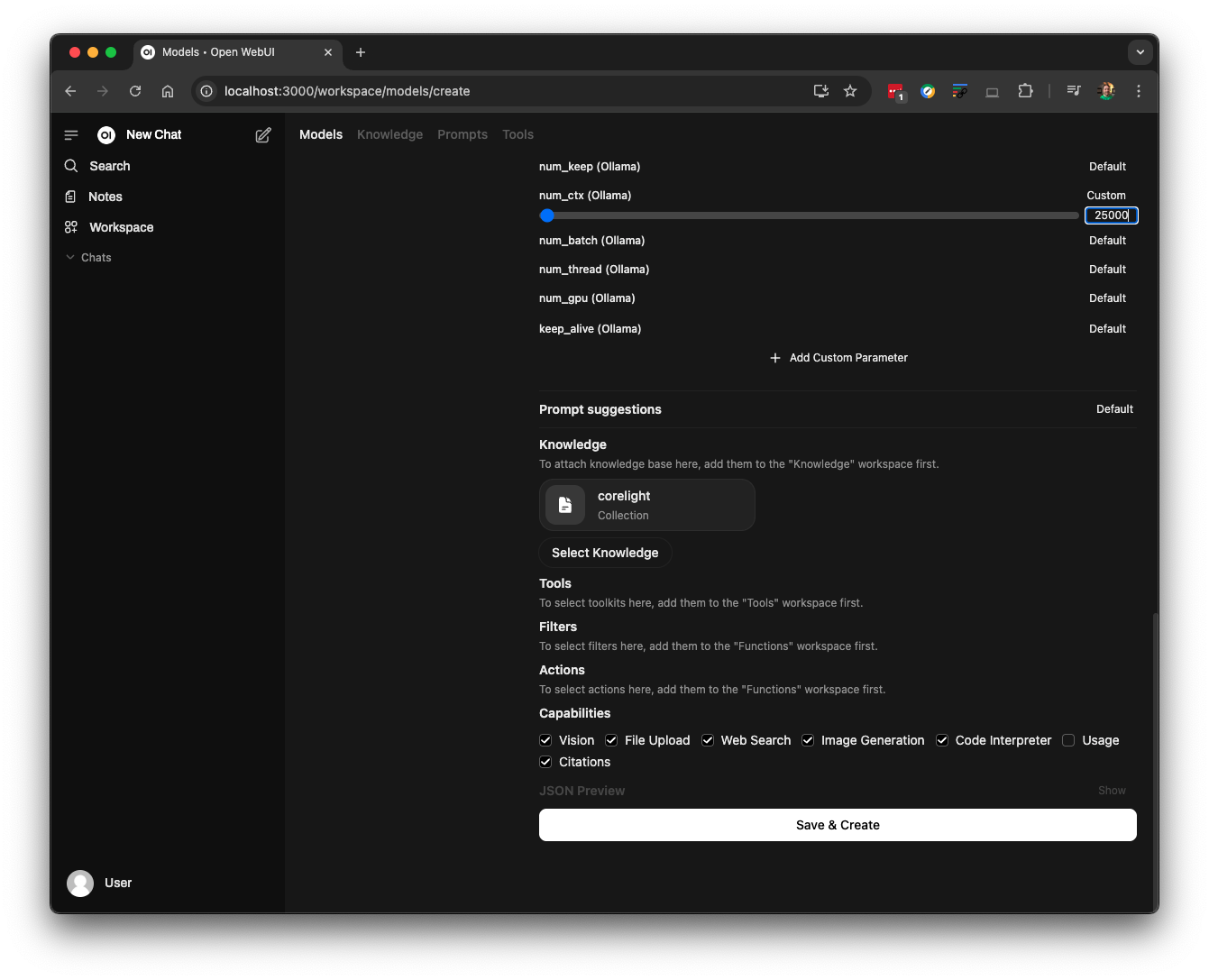
I also adjusted the LLM context size, which dictates the fixed RAM the model occupies on your machine. A 25,000-token context size utilizes approximately 17GB of my laptop's GPU RAM, minimizing reliance on the slower CPU for computations. Configure this value according to your system's specifications and then save the model. If necessary, you can use "ollama ps" in a command prompt while querying the LLM to observe RAM allocation.
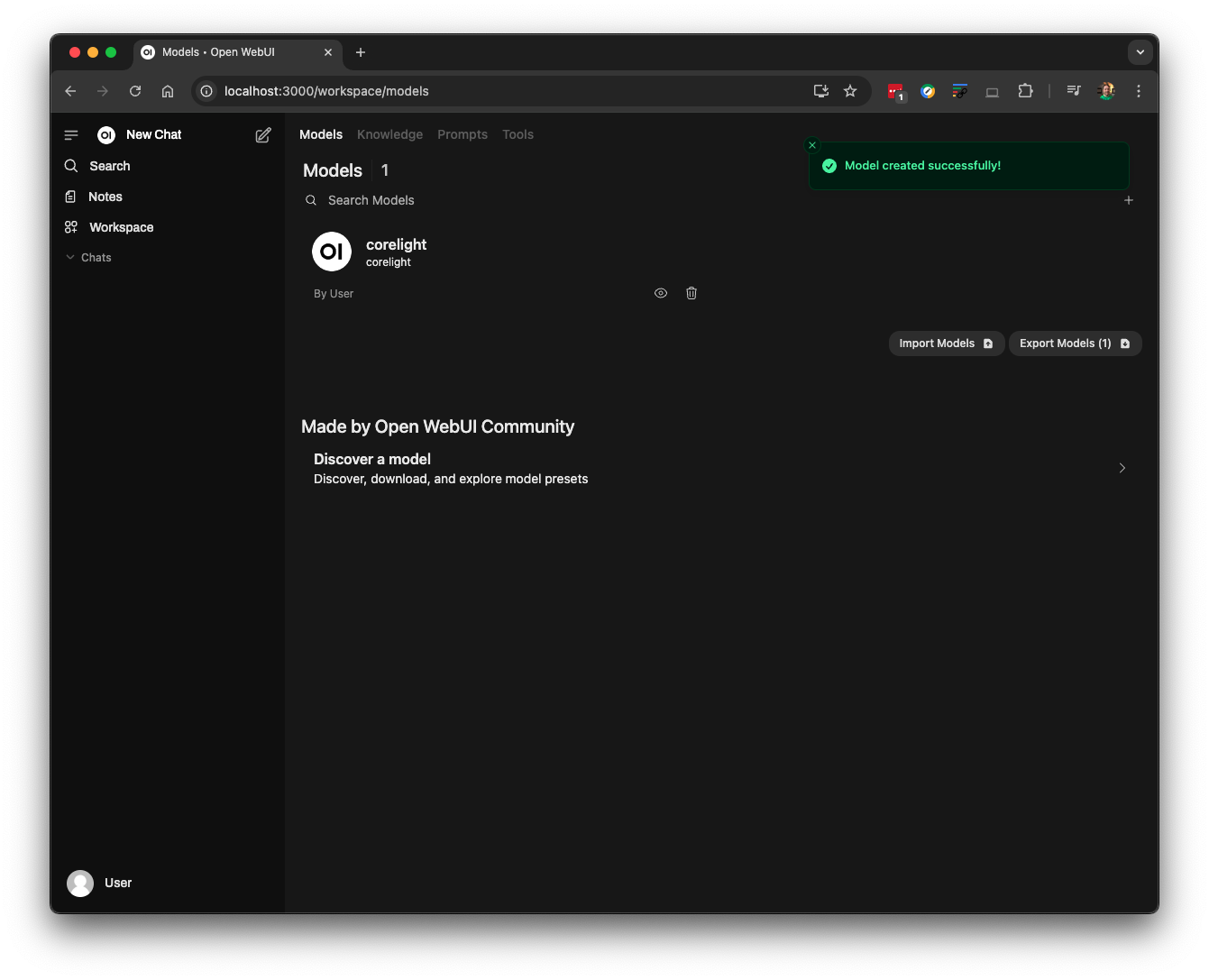
Now, save your new model:
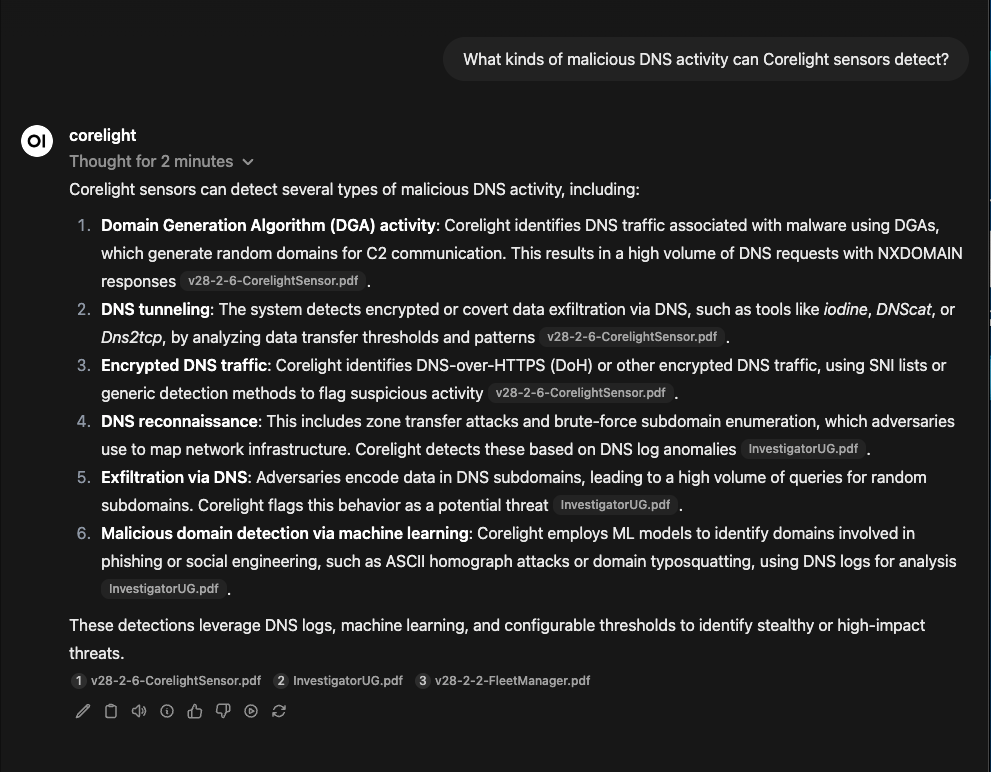
To initiate a new chat, select "New Chat" and choose "corelight" from the model dropdown at the top. Enter your query, and the LLM will leverage the knowledge base to provide an answer. For instance, you can ask what types of malicious DNS activity Corelight sensors are capable of detecting.
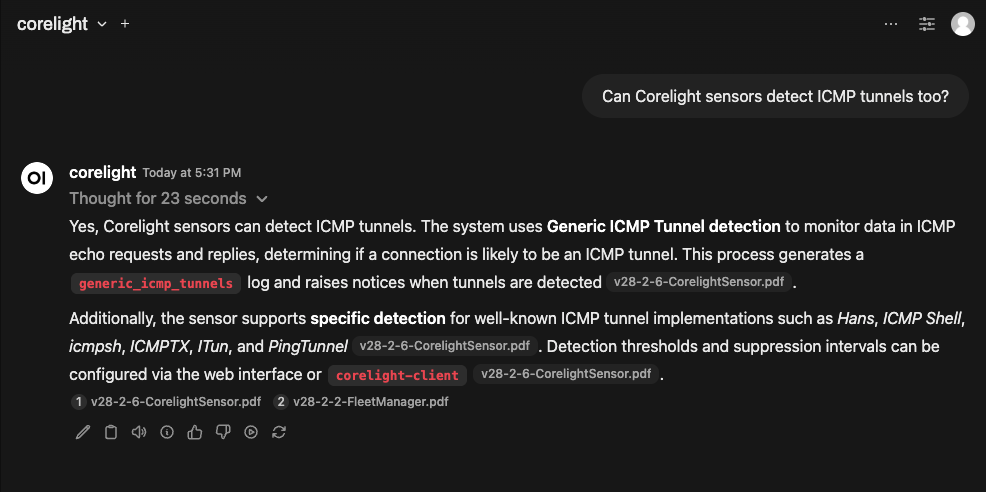
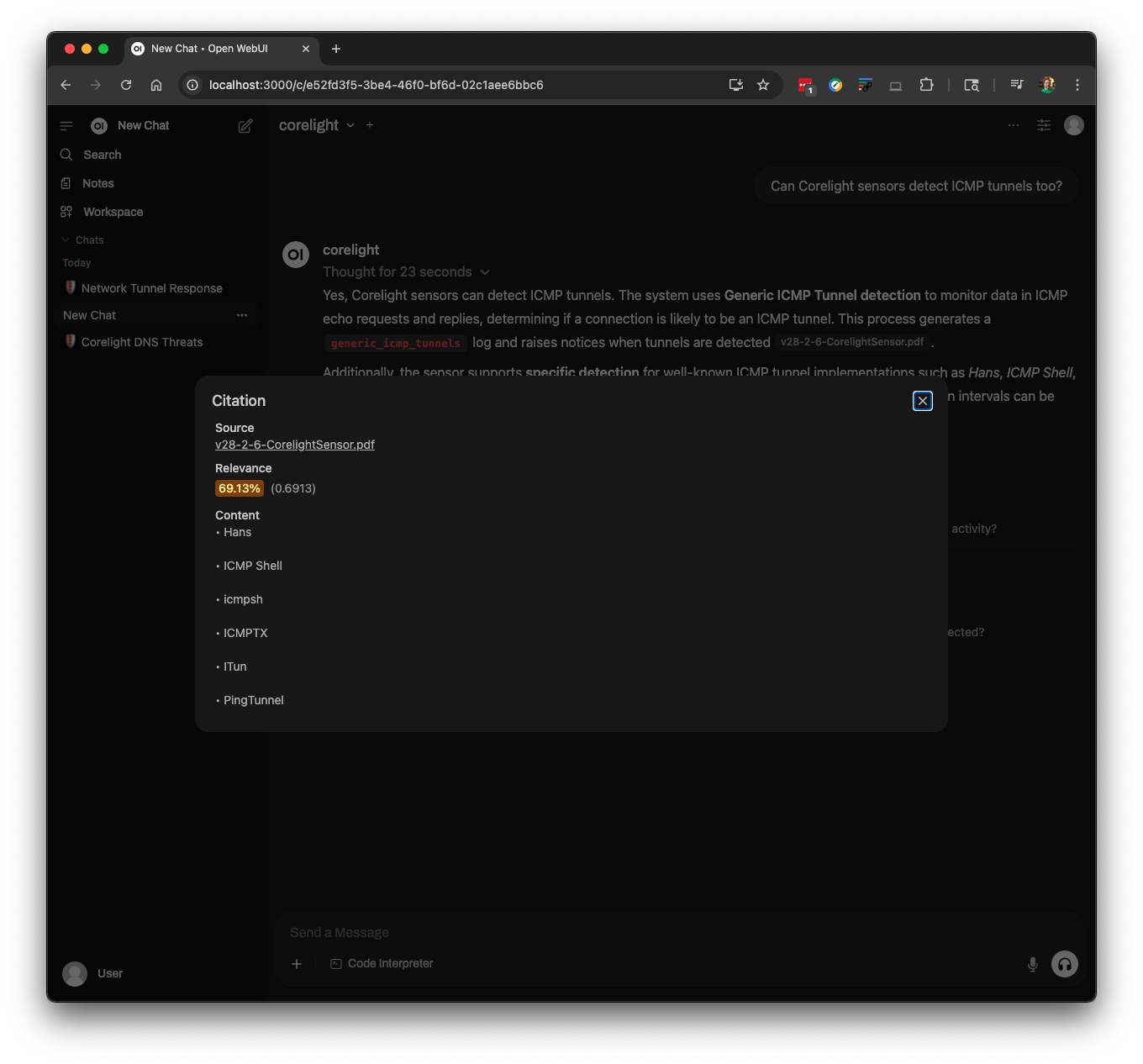
Here is a query asking about ICMP tunnel detectors in Corelight sensors:
All of the citations in the outputs are clickable, so you can see where the LLM got the information from your knowledge base:
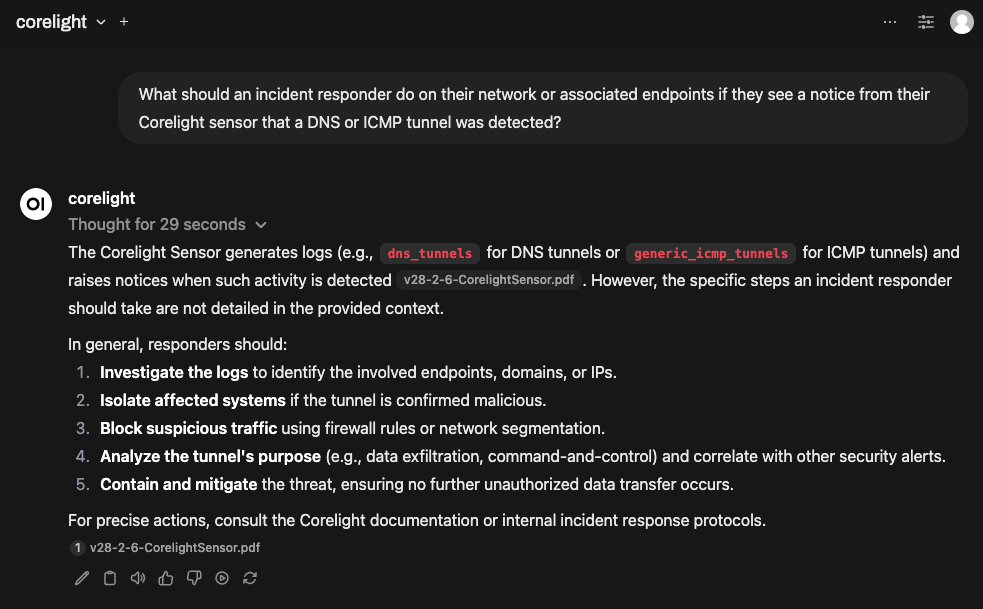
You can then ask the LLM more complex cybersecurity-related questions, like what one should do if a Corelight sensor detects a DNS or ICMP tunnel:
As illustrated in the screenshot above, the toolkit's strength lies in its ability to leverage LLMs to provide cybersecurity insights that extend beyond the scope of the input content. While Corelight user guides did not explicitly detail remediation steps for DNS and ICMP tunnels, the LLM was able to analyze the relevant guide content and suggest the necessary actions. This demonstrates how LLM integration can significantly enhance cybersecurity analysis.
Switching gears, if you want to analyze some Zeek source code with an LLM, you can analyze the open-source AgentTesla malware detector that Corelight published, following similar steps to the Corelight sensor user guide example:
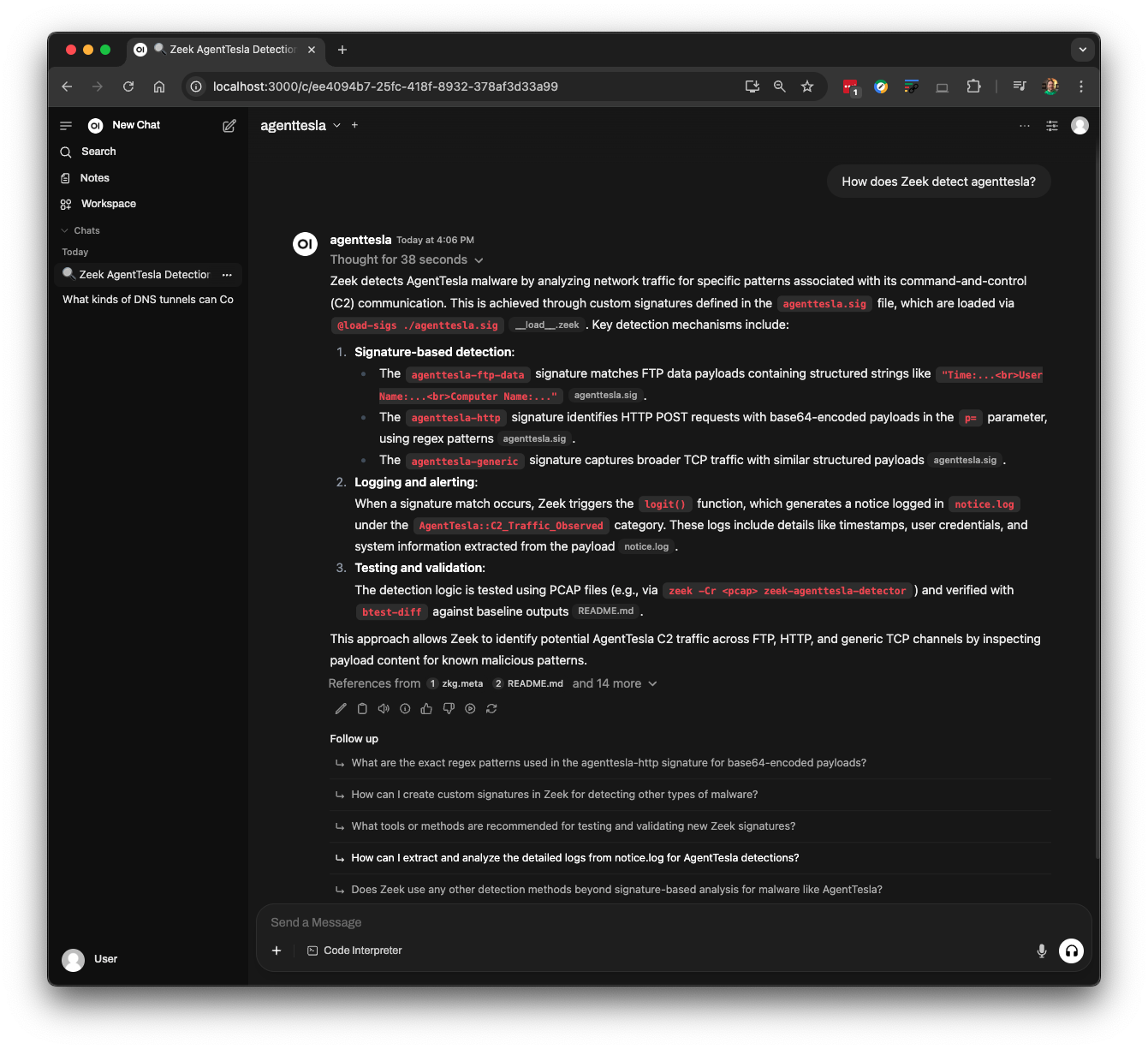
…you can even ask the LLM technical questions about Zeek source code:
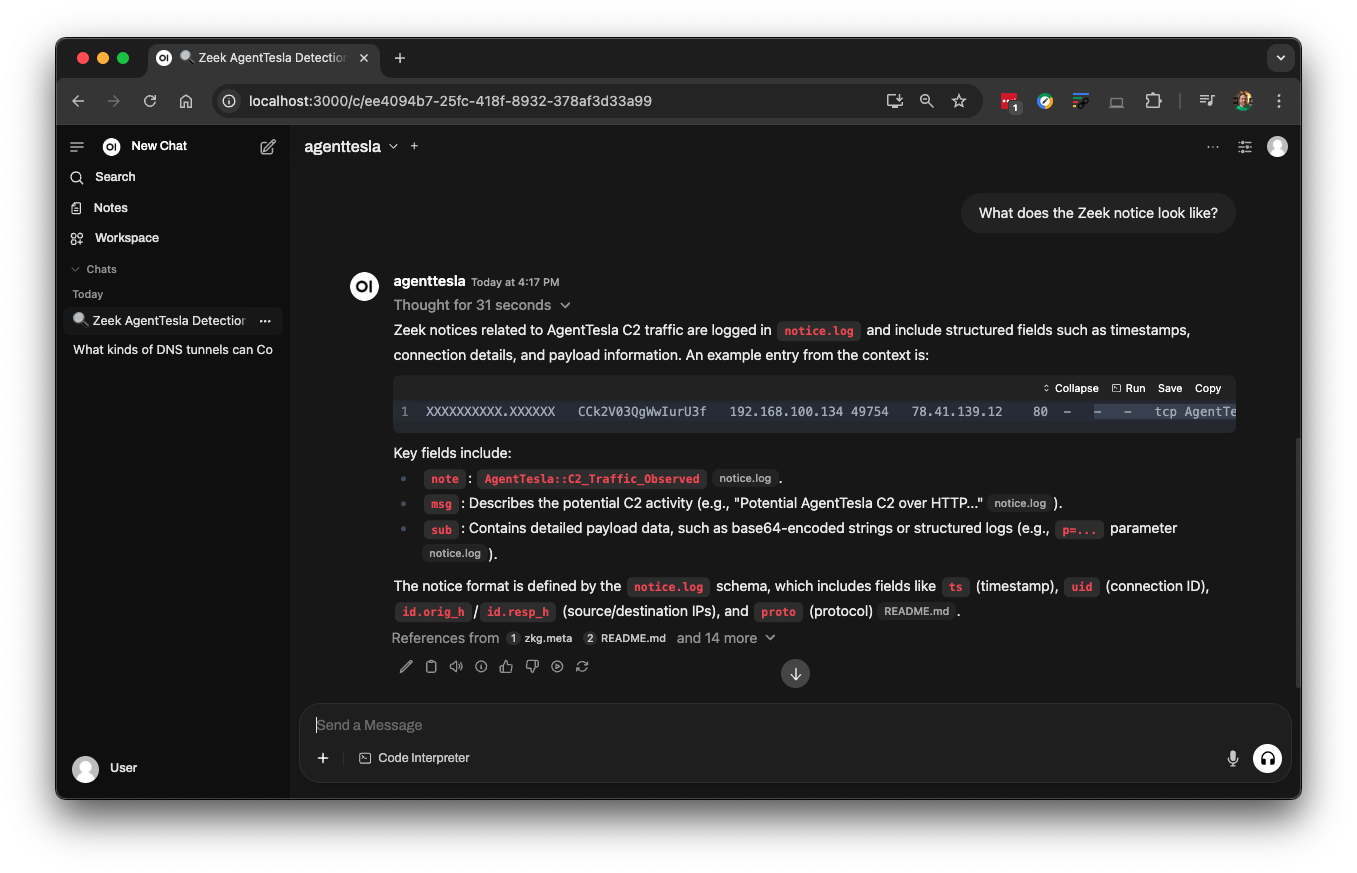
It is important to note that you don’t even have to understand Zeek’s programming language to get these answers from an LLM. Here, the LLM correctly explained what types of strings related to AgentTesla malware Zeek looks for in network connections, and if detected, the specific Zeek notice that is generated.
We can even ask the LLM for example notices generated by the AgentTesla detector:
If you prefer to add your files programmatically to an Open WebUI knowledge base, you can use this LLM-Ninja script I wrote to do exactly that:
https://github.com/corelight/LLM-Ninja?tab=readme-ov-file#open-webui-knowledgepy
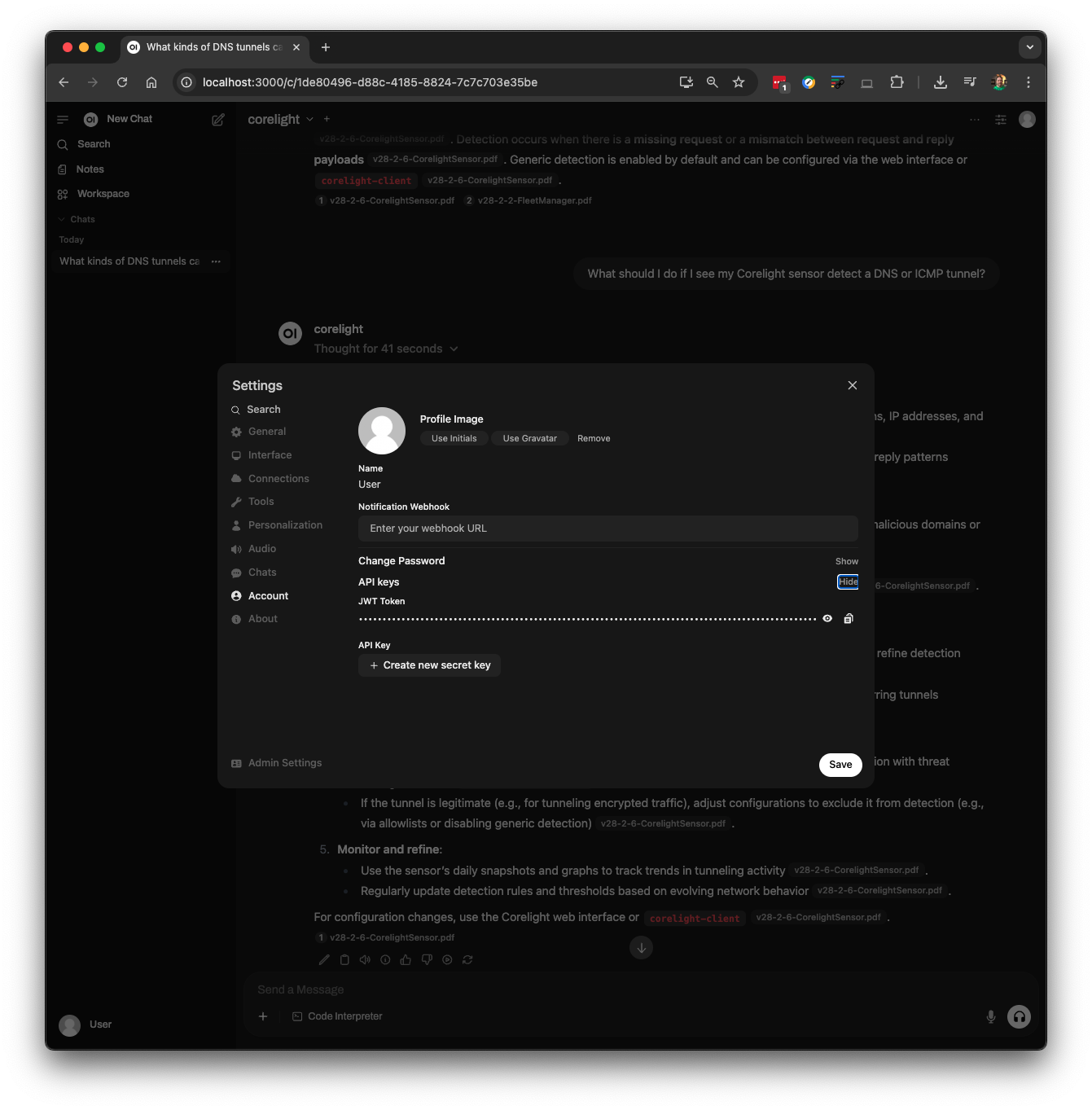
After setting up your Open WebUI instance, create a knowledge base, and then get your JWT (JSON Web Token) security token by navigating to Settings -> Account in the upper right-hand corner:
Use the JWT key with the Python import script, specifying it via the `-t` token command-line argument. The knowledge base name (e.g., "corelight" and “agenttesla” in my examples) should be provided using the script's `-k` argument. To filter by input file name, such as importing only specific file extensions, use the `-p` regular expression pattern command-line argument. An example command line for running this script is available at the provided GitHub link above.
This blog demonstrates how to significantly enhance the capabilities of your LLMs by integrating them with Open WebUI knowledge bases, particularly for specialized domains such as cybersecurity. By following the steps outlined, you can set up a robust system that allows your LLMs to intelligently query and retrieve information from your custom, confidential content. This approach not only expands the knowledge of your LLMs beyond their initial training data but also ensures data privacy by keeping your sensitive information on your local machine. The examples provided, detecting DNS tunnels and analyzing Zeek's AgentTesla detector, highlight the practical applications and the profound insights that can be gained. Whether through manual file uploads or programmatic imports, empowering your LLMs with a dedicated knowledge base is a crucial step towards unlocking a new level of intelligence and critical insights in any specialized field.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}