network security
Detecting Quasar Windows RAT
Detect Quasar RAT malware with Corelight’s open-source Zeek script, leveraging Quasar’s default TLS configuration.
Recently a very interesting Linux-based command-and-control (C2) malware was described by the research team at Intezer. As usual there is a set of simple network-based IOCs in the form of domains and IPs that organizations can search against their Zeek dns.log, http.log and conn.log. Using Zeek, detecting this threat at a deeper layer is also relatively straightforward, and this C2 provides a good demonstration of how to use Zeek’s ability to extensively track state to augment simple IOC-based logic.
The ability to create behavioral-based detections – such as the state-based detection as described in this blog – is a powerful option because threat actors can easily change traditional IOC factors (e.g IP address, URL and domain names) which results in simpler IOC-based detections failing. Another benefit of using lower level behavioral detection logic is they are vastly less prone to false positive detections.
Let’s start with a few interesting points about this malware:
The implant is specifically designed for Linux systems, having been compiled on a legacy compiler which is the default on RHEL6 – this may be of interest to those in threat intelligence and perhaps those seeking attribution, but is not further relevant to this detection.
This malware, like many others, uses HTTP as a C2 channel. While modern C2/exfiltration traffic is often encrypted, it’s not always being sent over HTTPS. “Pre-encrypted” data can be sent using POSTs over HTTP. While we certainly have other tools to help shine a light on encrypted network traffic, we should not neglect good old HTTP analysis – even today.
RedXOR payloads and exfiltration can be decoded with enough effort, as shown in Intezer’s research. However we don’t have to rely on the payload being decoded, we can treat RedXOR as yet another example of malware “pre-encrypting” data and then sending that encrypted data as HTTP – for example, as Emotet does [1] [2].
The C2 sends commands to the implant within HTTP cookies. For the purpose of this detection, we will focus solely on commands used in the registration of the C2 implant (highlighted below).
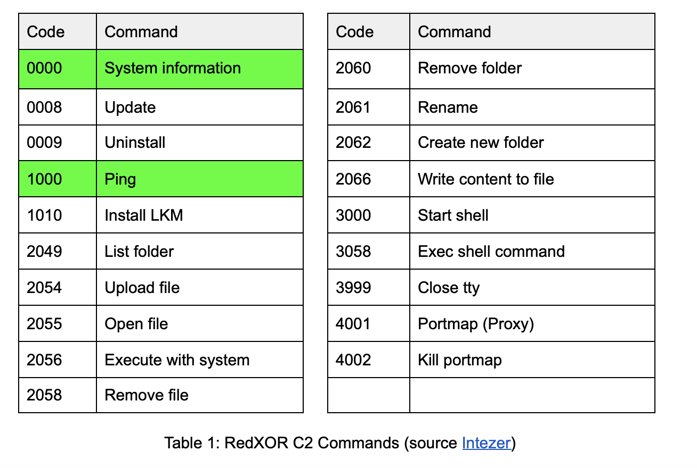
The detection logic we use in this demonstration involves looking for a consecutive pattern of cookie transactions between the Implant and the C2 as follows:


This series of cookies indicates an initial infection. We can use similar state-based logic for other cookie values that represent the various commands that may run subsequent to infection.
Zeek is an event-based engine, which means Zeek runs particular code only when it sees an associated network event occur. In our case we are interested in inspecting HTTP cookies, and these are passed within HTTP headers. The most relevant Zeek event is http_all_headers. This event provides us a mime_header_list called hlist. We simply need to fish out the cookie component from mime_header_list by referencing the correct element, and then check whether what we find is the next in the sequence we are looking for. This is the only Zeek event required to detect this threat.

We have heavily commented the script itself (https://github.com/corelight/redxor) to explain the logic at a low level, and we’ll also cover a few key points here.
The script creates a state-keeping variable and attaches it to each HTTP connection. It is aptly called c$http_state$redxor_cookies_seen_so_far and it keeps track of how many matching cookies we’ve seen so far in that connection. When it reaches five we know that we’ve seen all five cookies in the correct order and we raise a “notice” in notice.log.
Keen reviewers of the code may note that a proxy can potentially add and even reorder headers, and so the cookie won’t also be in the same location. This can be readily accounted for by cycling through each element of the header list to find the cookie header. However so as not to over-complicate this demonstration, let’s assume that the headers are not re-ordered.
Since all the pieces required for this detection exist in the same TCP connection, they all share the same Zeek uid, which has two important consequences:
c$http$trans_depth to determine how far into the HTTP connection we are. There are two header lists per trans_depth – one from client and one from server. Since we are only looking for the first five cookies, these will be contained in the first three trans_depth as shown below.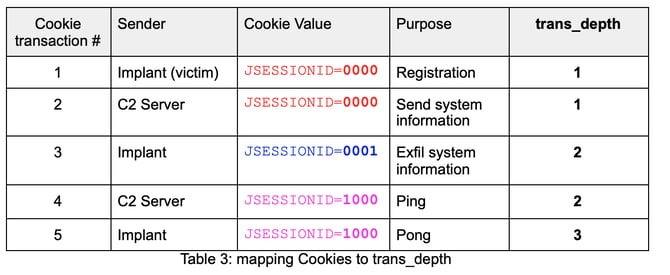
In a busy network with a lot of HTTP headers, http_all_headers will occur a great deal, so it’s helpful to look at some tactics to ensure that the script doesn’t waste resources. A good reference for performance tuning is the “Profiling in Production” presentation by Corelight’s Justin Azoff at ZeekWeek 2019. Note that I’m not an expert at Zeek performance, and I’ve only learned some of these things the hard way and with expert advice from fellow Corelighters – so I’ll share some of the things that have become part of my workflow as I build out a detection like this:
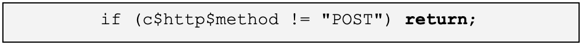


trans_depth > 3 we can return straight away. This is important because a lot of HTTP sessions have high cardinality here. This is also not an aspect that surfaces easily during script testing on a small pcap – it’s often only when you run the script at scale that these issues will arise, so it’s a good habit to put bounds checking into your script development mindset.
Having a super-performing script that misses your pathological case because a logic bug snuck in while you were performance-tuning to the nth degree isn’t the goal! Making things more efficient at the expense of readability, simplicity and workability is a balancing act in my humble opinion.
There are various other ways to detect this malware with Zeek, and we build detections like this into the Corelight C2 collection. This script has been prepared as a tutorial-style demonstration of one such technique, as it highlights how Zeek’s state keeping can be used as a fairly intuitive and practical way to detect modern C2 malware, as well as demonstrating some performance issues to keep in mind when writing Zeek scripts yourself.
Credit to Intezer for their research on RedXOR and their collaboration with us at Corelight. Refer to this writeup for a low level description of the malware:
https://www.intezer.com/blog/malware-analysis/new-linux-backdoor-redxor-likely-operated-by-chinese-nation-state-actor/.
The script was prepared from an abstraction of the actual pcap (which could not be shared in its native format due to sensitive information contained within). This abstraction was prepared by the Intezer Research team and shared with Corelight Labs for the purpose of writing this demonstration.
#Linux #C2 #RedXOR #HTTP