Zeek
How we decide what Bro capabilities to include in our Sensor
When we developed our commercial product we made some design decisions that make running the Corelight Sensor slightly different from running...
I often develop packages for Zeek in cluster mode. In this configuration, it can be difficult to debug your package because it is a continually running environment with real, and often unpredictable, network data. If you add to that other packages that might be running on the cluster during testing, it can be difficult to determine if memory usage is associated with your new package or something else that might already be running on the cluster. In this post I am going to walk you through the process I used to develop a package called “my_stats” that pulls memory information from a running development cluster. The source code for this article can be found at https://github.com/corelight/my_stats and installed using zkg with the following command:
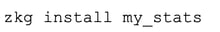
The first component of our package is a Zeek function called “global_sizes” (https://docs.zeek.org/en/current/scripts/base/bif/zeek.bif.zeek.html#id-global_sizes). This function returns a table where the index is each global variable name (including the variable’s namespace), and the value is the size, in bytes, that variable uses. Here is an example run of this function on https://try.zeek.org/:
Input:

Output:

As you can see, this is the type of data that will be useful for a package developer, right? If we can dump the output of this function to a new log on our cluster periodically, we could use the information to find the packages that use the most memory on our cluster. Hopefully it will not be the package we are developing!
This article assumes you have basic knowledge of Zeek and writing packages. If you would like a refresher, the following documentation is a great resource: https://docs.zeek.org/projects/package-manager/en/stable/package.html. The first step to creating a package is making a git repository named “my_stats” with a file “zkg.meta” with the following content:

The zkg.meta file gives our package a description and tags. It also points to where we are going to store our scripts, which is a directory named “scripts” appropriately enough. Create this directory and create a “__load__.zeek” file in it with the following content:
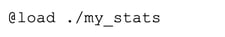
This will load a file called “my_stats.zeek”, which you should also create in this directory. The my_stats.zeek file will contain all of the logic for our my_stats package. We will walk through the creation of this my_stats.zeek file next.
First, define the module with the following line:

Next, for exports include the new log file we are going to write to:
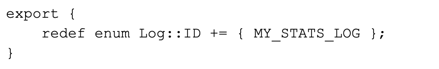
This means we must create this log stream, which we will do in zeek_init() after we define the columns of the output log file. The content of the log file is dictated by MyStatsInfo, and it must be first defined as the following:

Our output record will have the time, the sequential execution number (run) of global_sizes(), the node this information was measured on, the module name for the variable, the variable itself, and the size of the variable.
We define zeek_init() with the following lines:

Our zeek_init function will create the my_stats.log with the columns identified in “MyStatsInfo”. It also schedules an event called “dump_global_stats()” in 10 seconds.
In order to track our execution run, we will create a new global variable too:

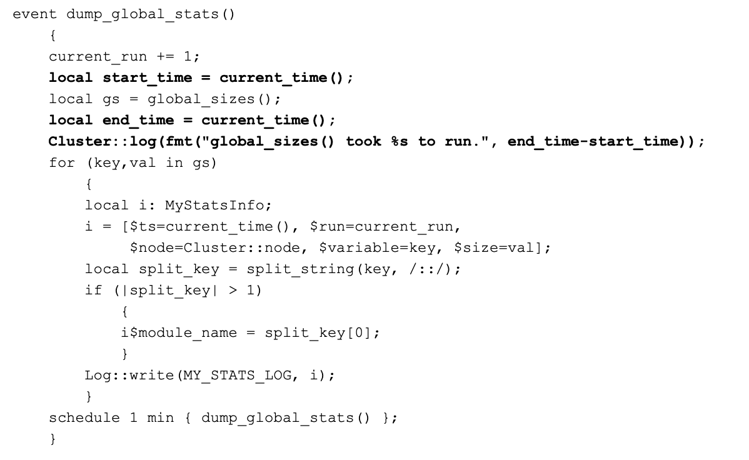
Lastly, we just need to create the logic for the dump_global_sizes() function. This function will first increase the current run before it iterates through all of the variables returned by global_sizes(). The function will then take each variable and format it into the output record we discussed above. Then, it will attempt to extract the module name from the variable by splitting on the “::” separator. Lastly, this function will schedule itself again to run a minute later. Here is the content of dump_global_sizes():

Now, you will need to commit all of your changes and install the package with:
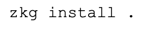
Next, deploy your cluster with zeekctl and my_stats will start collecting information for you. Here is part of a log from a cluster I run locally:
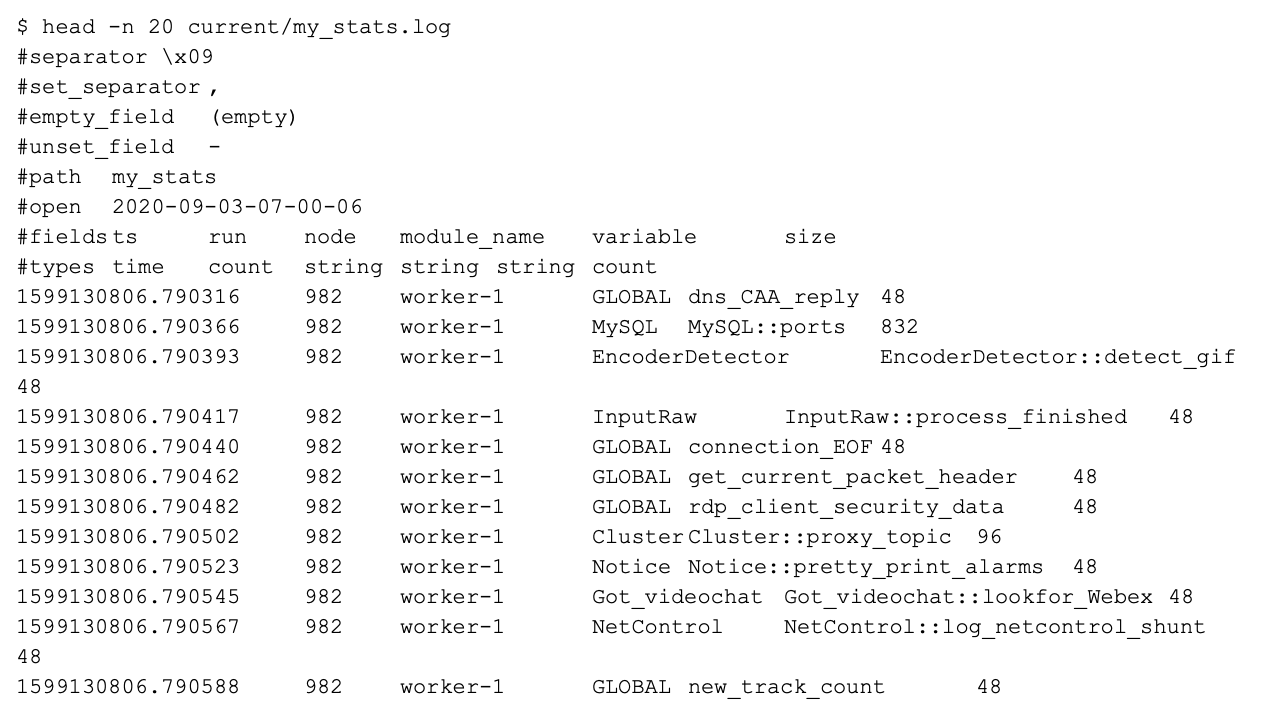
This is exactly what we need! You can see I have been running this package for a while as my run is #982 above. We can now use this log like a giant spreadsheet with Unix tools such as awk, grep, and cut. If we want to see how many bytes each package on my machine uses, we can use the following Unix command from the logs directory:
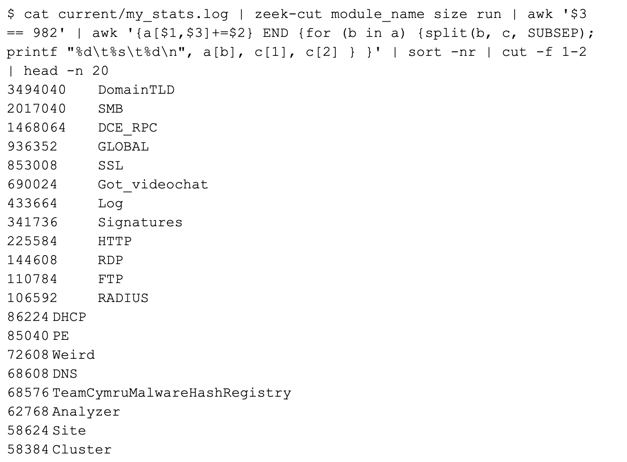
On my system you can see the package “DomainTLD” (https://github.com/sethhall/domain-tld) uses the most memory at approximately 3.4MB, followed by SMB, DCE_RPC, the GLOBAL variables, SSL, and others. If I was developing DomainTLD, I would know immediately that my package was using the most memory on my cluster. Neat, right? This is not picking on DomainTLD, as it is just the package at the top of my list for this example. We can look at other views of the same data to get a better picture of what DomainTLD might be storing by modifying our previous command slightly:

We see that “effective_tlds_2nd_level” uses the most memory at approximately 2MB, followed by the 3rd level at approximately 1MB, followed by other variables. Lastly, we might care about memory usage across the different nodes within our cluster. Our package allows for us to do that analysis too:
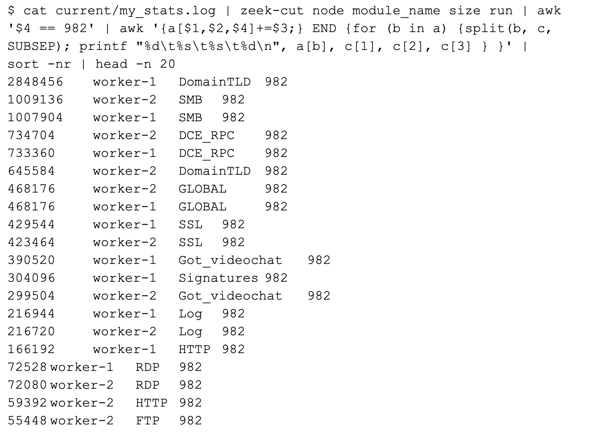
We see that DomainTLD uses the most memory on the node named “worker-1”.
The last thing we want to keep in mind is global_sizes(), the function that collects all this great memory information for us, can be expensive computationally. If you are in an environment where you are already (or close to) experiencing packet loss, you might want to reconsider if you want to install my_stats. On one hand, you might find packages that are using more memory than you thought and you could optimize your cluster. On the other hand you might not, and my_stats could contribute to the packet loss problem because it takes a while to run global_sizes(). Therefore, I recommend that my_stats be run on non-production environments for the purposes of debugging during development. We can add some metrics to our code to see how much time it takes to run global_sizes() on each node by modifying dump_global_stats() to be the following (changes are in bold):
Now if we examine our “cluster.log” file, we will see the following on my local cluster:
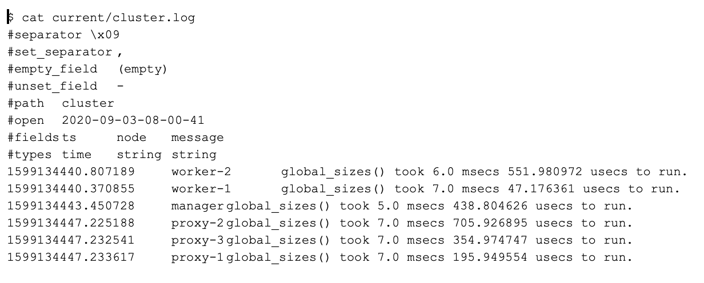
You can see that each execution of global_sizes() is around 7 milliseconds. We could reduce the load on our cluster if we run this function less often. This can be achieved by first exporting a new global variable:
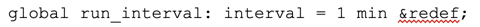
Then, modify the schedule line in dump_global_stats() to the following:
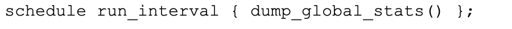
Now, the interval for calling global_sizes() could be controlled from outside the my_stats module by redefining my_stats::run_interval. You could change the interval to more than 1 minute to reduce the load on your cluster.
One last thing we can add to our code is a filter to remove small variables from the output, to reduce the number of lines written to the log to just the bigger variables. Since we are looking for really large memory usage, we can remove variables that are less than 1,024 bytes by adding a threshold in our exports section:

Now, edit your dump_global_stats() function to the following (changes are in bold):

After deploying this code, your variables in the log will be greater than or equal to 1,024 bytes. Change the “min_var_size_to_log” variable to zero to log everything.
A last caveat about global_sizes() from the authors of Zeek: global_sizes() can return sizes that are ballpark due to a number of platform specific technical limitations. This caveat does not reduce the usefulness of my_stats, as prior to this package we had no simple method to pull the memory profile of all global variables.
I hope you found this post useful and if you have any questions you can find me on the Zeek open source Slack server.