Zeek
Don’t delay – Corelight today!
While I have used log collection and SIEM platforms to review Zeek transaction logs, it is not necessary to wait for a SIEM before collecting...
Editor's note: This is the fourth in a series of Corelight blog posts focusing on evidence-based security strategy. Catch up on all of the posts here.
Evidence is the currency cyber defenders use to pay down security debt, balancing the value equation between adversaries and the enterprise. Defenders can use network evidence proactively, identifying and protecting structural risks within our zone of control. Evidence can also be used reactively by supporting detection (re)engineering, response, and recovery activities, guiding us back to identifying and protecting structural risks. It is impossible to avoid a security event, but which side we spend most of our cycles on is dependent on our overall data strategy and how we nurture our evidence.
Much has been written on data lakes and data marts. Corelight has previously discovered that for a number of organizations one SIEM is not enough. Organizations often implement a data collection strategy out of fear, collecting everything “just in case.” I challenge the assumption that we must collect EVERYTHING and determine its usage at the point of incident.
Defenders have a responsibility to proactively inform the business of risk to the organization or reactively provide evidence to mitigate realized risk. Our ability to gain decision advantage over adversaries will depend on the selection and conversion of raw data into accurate decision-making knowledge. We view the world through two lenses: the structural context of our organization and the situational context that exists within the structure. Sounil Yu provides a framework that effectively captures the balance between the asset classes we’re enlisted to protect and the activities that defenders perform in the Cyber Defense Matrix. He goes on to contextualize activities as left and right of “boom” with boom signifying a security event. The identify and protect (left of boom) activities are focused on the structural context related to risk in the organization. The detect, respond, and recover activities (right of boom) are largely based on situational context related to risk.
Security teams leverage vendor support or self engineering to convert raw data into actionable intelligence through some number of operational processes. The net result of those actions catalyzes protection or response initiatives across the organization. If we reframe our thinking, we can recognize this is a supply chain. Strong risk assessment activities (threat modeling, penetration testing, compliance engagements, etc.) are fundamental to developing the use-cases (products) our cyber security supply chain supports.
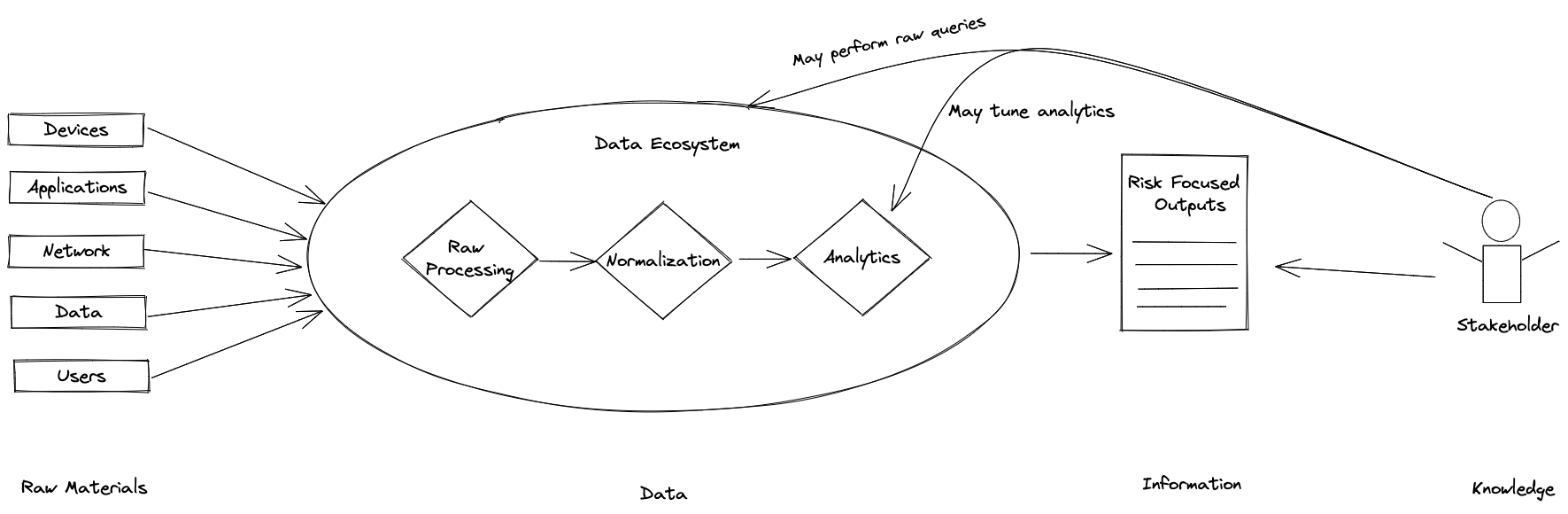
A complete data strategy allows an organization to work backward from risk to raw logs and create a supply chain that generates information critical to risk reduction activities. It is imperative that your data strategy includes the following attributes:
The choice of a data lake, data mart or leveraging a SIEM is dependent on your individual environment, previous investments and stakeholder requirements. However, it is imperative that we view our data and evidence as raw materials in the intelligence supply chain and seek opportunities to extract maximum value. In all cases, we leverage the currency in our evidence bank to buy us time through proactive structural change or to buy our way out of unnecessary adversarial impact.
By Bernard Brantley, CISO, Corelight