NDR
Corelight Open NDR Now Helps Defend Black Hat Events
Corelight’s Open Network Detection and Response (NDR) solution has been chosen by the esteemed Black Hat Network Operations Center (NOC) to help...
During this year’s Black Hat in Las Vegas, I learned (or was reminded of) many lessons working alongside my Corelight colleagues and Black Hat Network Operations Center (NOC) teammates from Arista, Cisco, Lumen, NetWitness and Palo Alto Networks. The uniqueness of standing up a full security stack and NOC in such a short time with a team that comes together infrequently really forced me to consider how team processes and communication affect NOC/SOC efficiency and effectiveness.
Here are five lessons that me and my NOC teammates learned over the course of our week together:
Most of my time in the Black Hat Network Operations Center (NOC) was spent sifting through network telemetry and intrusion detection system (IDS) alerts, looking for notable, interesting, or malicious findings. As such, we started with the best thing suited to the task: Corelight’s Open NDR Platform, powered by Zeek® and Suricata®. Open NDR’s Zeek engine took the network traffic and created log entries detailing what happened in human-readable, indexed text from which we could easily search and make tables, charts, and graphs. Its Suricata engine used the ProofPoint Emerging Threats Pro ruleset and compared it to the network traffic to point out interesting actions or behaviors that might indicate malicious activity.
Frequently, I hear that many people want IDS rule sets to be “set and forget,” even out of the box. However, I believe that history has repeatedly demonstrated that the sensitivity level of any detection system exists on a continuum that runs from “set and forget” to “catch everything.” The issue is you have to choose a place on that continuum, and no matter where you are, you’re trading ease and simplicity for comprehensivity, or vice versa. The more you move the slider toward “set and forget,” the easier maintenance will be, however you’ll also miss advanced or novel attacks, which defeats the purpose of intrusion detection. On the other hand, the more you move the slider toward “catch everything,” the more things you will catch, which unfortunately means that you’ll need to spend more time tuning, whitelisting, and triaging out the things that are irrelevant to you at the time. As a result, no one IDS rule set can be applied to every organization unilaterally, because each organization has a different risk profile and different threats for which they would need to be vigilant.
In the case of the Black Hat NOC, we started with most rules enabled in the rule set, and then were quickly able to identify and turn off many rules that were not actionable under any circumstances on the network we were monitoring. However, what came next may surprise you: we got a ton of alerts for exploitation attempts, and for the most part we did nothing about them.
What?! Are you crazy?!
You see, we were protecting the Black Hat network where a number of classes being taught on-site were about “black hat” techniques; so, essentially, we were only considering an exploit to be malicious if it was used to attack for personal gain. Most of that traffic was from classrooms and directed toward resources that were in-scope for the students. It was only when Black Hat network users deviated, attacking out-of-scope properties or each other, that we had to intervene. There was no way we could have just set up an enterprise next-generation firewall (NGFW) with the recommended “block everything malicious” profile without creating constant major outages for the students and instructors.
So while on the surface it may seem like a typical “block-everything-malicious” profile would work for your organization, the truth is that eventually it will cause an interruption of service or a negative business impact, requiring you to do some serious tuning. My takeaway? Make the tuning part of your ongoing engineering efforts—set it, but don’t forget it.
In dealing with intrusion detection systems, and really any detection-oriented system, the terms “true positive” and “false positive” come up frequently. It comes from the two-dimensional matrix where one axis is “was it detected?,” and the other axis is “did it happen?”
This is all well and good, but I hear a lot of different people meaning different things when using the same terms. For example, I have heard the term “false positive” refer to all of these situations:
If we examine the various meanings for “false positive” that are listed above, it’s possible that a single security team may end up with some vastly different conclusions about what to do with a detection that is a “false positive”:
The issue I see is that calling all of these different scenarios “false positives” makes it difficult to measure the effectiveness of detection systems over time, and can even cause confusion about how to respond and react to a given alert or detection. For example, if I’m discussing an alert with a teammate and they say “I think that’s a false positive,” I might interpret this statement differently than my teammate and therefore make a different assumption than my teammate about what we should do. For this reason, I believe teams need to be discussing at least three distinct facets of the detection to bring clarity to detection and response:
Detections that are spurious due to faulty or inaccurate rule logic should be called “false positives.” Detections that are simply uninteresting should be called “true positive, not-malicious,” or TPNM for short, and should be tuned as appropriate.
If more organizations tracked things in this way, they could spend more time having meaningful conversations about how much of their energy is focused on detections that can and should be tuned out. As a result, organizations would waste less time on triaging alerts that are good detections but are uninteresting given the circumstances, allowing their teams to allocate resources to detection engineering or security analysis accordingly.
When making decisions, one piece of context could change, or even invert, the assessed severity and response actions for a situation.
While in the Black Hat NOC, we received an alert for a potential command and control check-in for a remote access trojan (RAT) called TripleNine from an internal IP. We thought that it could be an infected host, so we decided to investigate. Here’s what TripleNine looked like when we detected it using Corelight’s Open NDR Platform.
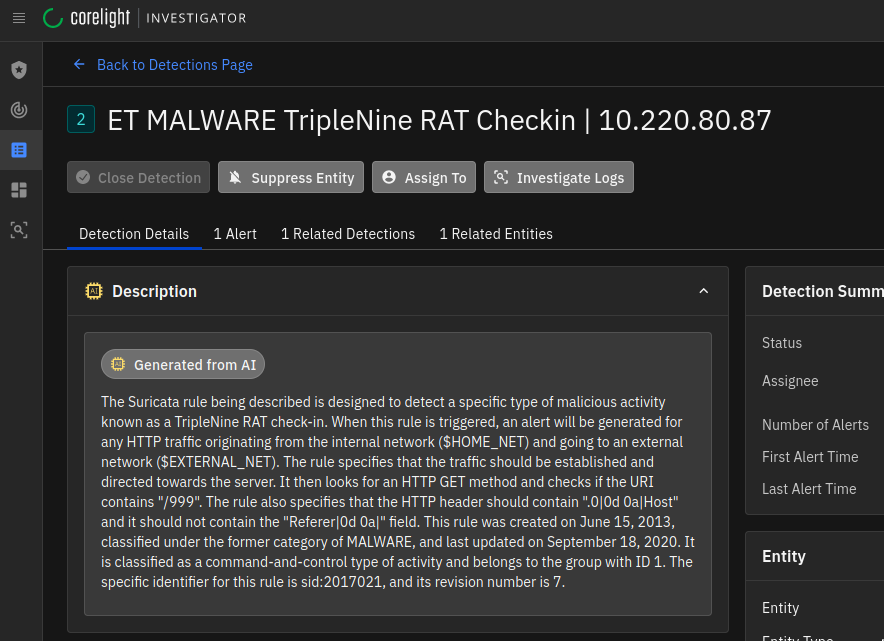
First things first, we had to make sure that the detection was accurate and that the rule detected what really happened. Based on the AI-generated rule description, we knew to primarily look for a request to a URI of “/999” on a request that didn’t have a Referer (yes, that’s how it’s spelled in the HTTP specification)—which is what happened here. Case closed, right?

Not so fast! While this was a “true positive” in the sense that what the rule was trying to detect actually happened, we were not sure that this was actually a check-in to the command and control server. Our NOC team decided to zoom out and check out the wider context. We asked ourselves, “What other HTTP requests could have happened between this source and that destination?”
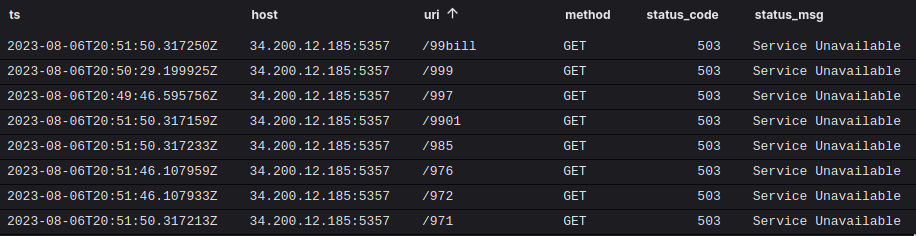
Once we zoomed out, it became clear that this wasn’t a check-in to a command and control server, but a client that was attempting to enumerate pages on a web server via brute force URI guessing or using word lists. So, while the described action did happen, it turned out it wasn’t actually a TripleNine RAT, and instead just a penetration test. If you are interested in an example of a true incident where we caught an infected host checking in to a command and control server from the Black Hat network, check out this article by my Corelight colleague Ben Reardon.
Later on, we also noticed a set of detections for a single host within our Open NDR detections page:
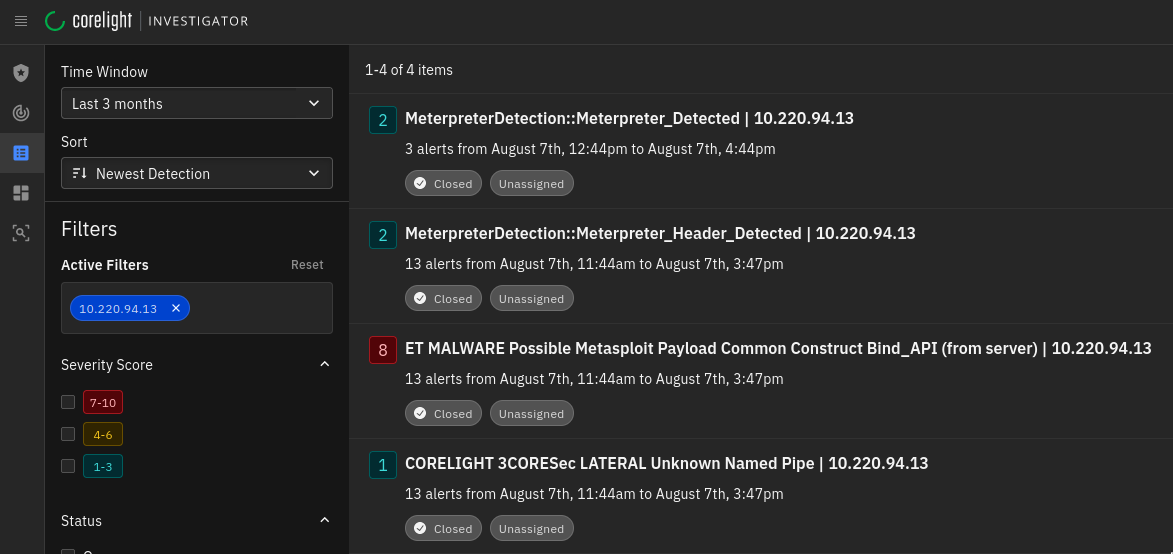
Here you’ll see that we had discovered a potential Meterpreter payload that was detected in three different ways, and an unusual named pipe that looked like a sign of intent to move laterally.
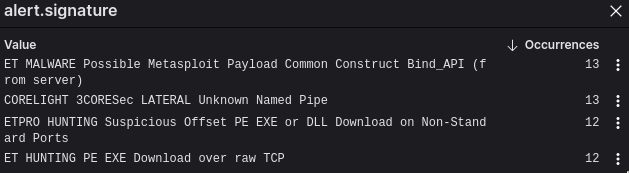
There were some more interesting things that we observed about these connections; they included EXEs embedded in the raw TCP stream, not as specific files, which we thought could have been tool transfer in a C2 channel. We decided to zoom out and see if we could passively figure out what domain this client looked up that was associated with that IP based on our passively-collected DNS logs:

We wondered, “Are more clients looking up that domain?”
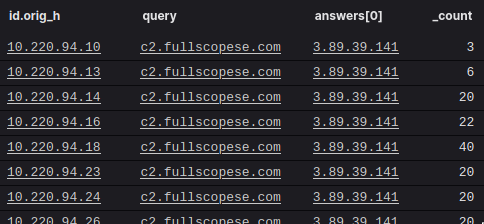
Lucky for our team, we had enriched our network telemetry with the name of the network that the connections came from:

To recap, we had connections involving Meterpreter and downloaded executable files in a TCP stream originating from a class called “Full Scope Social Engineering and Physical Security” to an IP address associated with the domain “c2.fullscopese[.]com.” Because we had the full context we needed to make informed decisions, it was much easier to say that this was more likely to be a behavior that was part of a classroom exercise or an instructor demonstration that was taking place that day during Black Hat, rather than a compromised asset or someone with malicious intent. If you saw these detections on your corporate network in a completely different context, I’m willing to bet it would be a far more dire assessment (but we can always hope you caught the internal Red Team).
When working with detections in a SOC, it’s very easy to fall into talking about things as if they are very, if not completely, certain. However, that gives us a false sense of control and confidence about what is happening in our organizations. In reality, we should be talking about:
Then, and only then, can we have a conversation about what to do next.
For example, let’s reassess the Metasploit detection I mentioned earlier in this article. In writing about it, I skipped straight to the leading theory of what happened, and didn’t expose any of the other hypotheses. Here is an expanded list of possibilities:
Note that I’ve mentioned six possibilities, and I haven’t even mentioned the instructor yet. To acknowledge my levels of certainty and uncertainty about what has happened, I’ll now list out the possibilities and assign them weights, essentially ranking them in order of perceived likelihood. In this case, I’ll assign them percentages, with the total being 100%. These are my opinions.
In this case, it illustrates that I’m not 100% certain of what happened, but points out what I believe is the most likely occurrence based on the evidence. As more evidence comes in, I may need to adjust my rankings, certainties, and maybe add more hypotheses.
If, in the process of discussing this with my team, I only talked about the top-weighted item, I may miss an opportunity to let a teammate see something I missed. Or, I could corrupt the conversation by causing my teammates to drop their own ideas in the face of my certainty. By making sure we talk about and consider more possibilities, we remain open to seeing new things, and to growth in general. We can still have a healthy debate and come to an agreement about what we collectively believe happened before moving forward, and we can be more confident in our assessment of the situation when it comes time to act.
One thing that amazed me about being in the Black Hat NOC was that we were a part of one giant team. However, it didn’t come without the temptation to work in isolation.
The issue with working in isolation is that it deprives the entire team of opportunities to:
There were several instances where I worked on a hunt or investigation, only to later realize that a teammate had already done it, so my effort could have been spent differently. There were times where I was stuck for a bit, showed a teammate, and they showed me something I had completely missed or would never have thought of. Other times I saw what a teammate was working on and realized that what I was working on should be shelved so I could help them work on their investigation, instead. All of those were opportunities for improved team effectiveness and efficiency. Most of all, though, I was surprised to be reminded that humans are social creatures, and that closing a ticket just felt better when I knew that I had worked on it with my friends and colleagues.
Want to read more about the Black Hat NOC? Check out these articles:
For more information about Corelight and how we can help your team disrupt attacks, please contact us.