Zeek
Finding SUNBURST backdoor with Zeek logs & Corelight
FireEye’s threat research team has discovered a troubling new supply chain attack targeting SolarWind’s Orion IT monitoring and management platform.
Network Intrusion Detection Systems (NIDS) are widely deployed by the most sophisticated blue teams in the world. For well-funded organizations, there is little question about the value of NIDS, but adoption is not uniform across the entire cybersecurity world. For many organizations, NIDS produce blinking red lights that are hard to contextualize, or they were set up years ago, and the person who knew how to leverage those systems is long since gone, and they now collect dust in the corner, silently eating CPU cycles.
A large part of the challenge is that NIDS requires effort. For better or for worse, they are generally not set-it-and-forget-it systems, and require tuning and thoughtful configuration in order to be valuable to a security organization. In addition, NIDS alerts are often not very useful in a vacuum. Contextualization of the alerts is key to both getting value out of a NIDS for incident response, as well as for providing a feedback loop into ongoing tuning efforts. In this blog post, we’ll look at some tips and tricks for how you can get more out of your NIDS today.
Most organizations are highly reactive with tuning approaches
The typical management process for NIDS starts with an organization picking up an off-the-shelf ruleset like Proofpoint Emerging Threats (ET) Pro or Cisco Talos. These rulesets are high-quality and extremely comprehensive, and have a huge number of rules out-of-the-box. The Emerging Threats (ET) OPEN ruleset contains nearly 28,000 rules. The commercially-licensed Talos and ET Pro rulesets each contain roughly 60,000 rules. However, the volume of rules also poses a challenge for organizations starting out, because these rulesets are not purpose-built for a particular sensor application, but rather are extremely general purpose.
The unfortunate reality of NIDS rules is that false positives happen. A vulnerability scanner might trigger tens of thousands of port-scanning alerts on a corporate network. The NIDS sensor isn’t wrong, but it’s not something that requires ongoing incident response. Sometimes a flow can look like one thing, but actually be another thing. For example, we’ve seen instances of organizations receiving thousands of Windows-focused alerts on a network segment that only had iOS devices.
Situations like these are mitigated by tuning rulesets, either through turning rules off, or suppressing or rate-limiting alerts based on some criteria. However, that process is extremely reactive, and often this tuning happens over months of spot-handling. By starting with a large ruleset, organizations may lull themselves into a false sense of security that bites them when they’re inundated with alert volume that becomes impossible to triage, and produces situations that make it easier for attackers to evade detection.
Proactive tuning will save resources and analyst time
For many organizations, it may actually make more sense to start with many fewer rules, and build a ruleset up over time. Instead of the potentially false sense of security that a large ruleset brings, you end up much more confident that you are watching for high-value alerts that are relevant to your estate and the traffic mix that you experience.
As an argument for thinning your ruleset, consider the fact that the security value of a rule is not static over time. The rules authored by Emerging Threats and Talos are often great rules, but not every rule is great the first time it’s written.
To elaborate on this, when a new major compromise occurs, rule writers rush out to write new rules to detect bad actor activity. As they learn more about the attacks, they refine, update, and revise the rules to get better and better. New rules often contain the weakest indicators of compromise (IOCs), and then get better over time, or are followed up with subsequent rules containing more durable detections. Thinking about this in the context of the Pyramid of Pain, the earliest rules are likely to leverage IOCs that are further down towards the bottom of the pyramid, like a malicious domain or JA3 hash. These IOCs tend to be the easiest characteristics to identify early on, but won’t survive long in the face of an active or sophisticated attacker. It often takes time to analyze an exploit to identify the deeper patterns that allow rule writers to design more durable detections, and so those often come with later iterations in the rules.
Additionally, a rule’s value may decline with age. Rules and detections for high-severity issues happening today might have extremely high value in the immediate term. A security risk on the order of Heartbleed, for example, is something that is so critical that you need to rush immediately to get rules onto your sensors. However, because Heartbleed was so severe, organizations were pushing out patches extremely quickly, and the level of public knowledge of the security risk was so high that there was both a steep ascent and drop off in terms of the value that the rules provide, as patches see widespread deployment.
Metadata makes proactive tuning easier
Suricata rules have a fairly well-defined structure, and there’s a good deal of information baked into the structure of the rule. Consider, for example, this rule:

The bolded information shows a variety of metadata fields describing the rule and what it aims to detect. Specifically, this rule is identified as something that is relevant at the perimeter, and affects a variety of Windows Server variants, and also details the relevant CVE that this detection focuses on. This information is extremely useful to a would-be rule tuner, because if a sensor is monitoring East/West traffic, or non-Windows systems, as an example, this rule doesn’t provide additional protection. However, it will certainly utilize some amount of computation resources.
The Emerging Threats team has begun adding highly-valuable metadata to their rules. To give a picture of this, the image below shows a series of pivot tables of metadata parsed out of the ET Open ruleset:
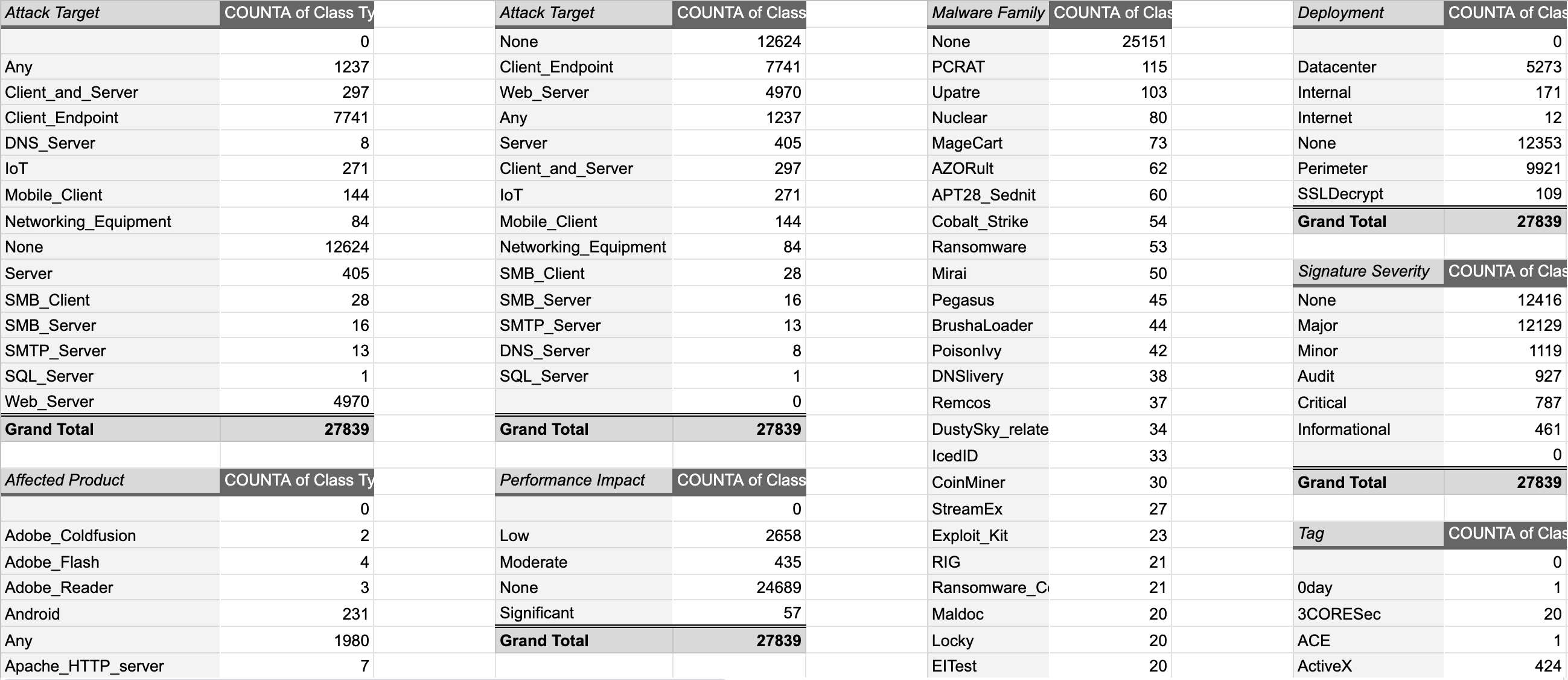
This information can be used to help choose the rules to apply to a particular environment or a sensor’s monitored estate. For example, if a sensor is intended to monitor North/South traffic, an ET Open rule focused on potential lateral movement, such as SID 2027267, “ET ATTACK_RESPONSE Possible Lateral Movement – File Creation Request in Remote System32 Directory (T1105)”, isn’t appropriate for this sensor. Rule metadata could be used to restrict a ruleset to just rules that are appropriate for North/South traffic by specifying the following in the disable.conf file used by suricata-update:

These entries will disable any rules that contain the text “deployment Internal” or “deployment Datacenter”. The Emerging Threats team uses these labels on internally-focused rules. Disabling these rules would remove about 5500 rules from your ruleset, freeing CPU time on the NIDS and reducing irrelevant alert generation.
This same approach can be used to disable rules based on rule age, by adding a line, such as the following, to disable.conf:
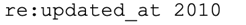
That statement disables rules that were last updated in 2010, which accounts for 4381 rules at the time of writing. While there might be a handful of rules that were last updated in 2010 that still have value, the vast majority of them will have long-outlived their utility.
Zeek pairs with NIDS to increase security utility and tunability
NIDS alerts, on their own, are rarely enough for an analyst to truly confirm or respond to a potential incident. NIDS are very good at drawing attention to malicious or unwanted activity, but can rarely be used to determine the scope of malicious or unwanted activity. This is why, in high-performing SOCs, NIDS are often paired with network traffic analysis (NTA) tools like Zeek, which generates transaction data (and can extract file contents) that help analysts put NIDS alerts in context. If someone is accessing a website, Zeek will tell you what DNS queries were run, what answers were provided, what URL they visited, and what resources they requested, if HTTP was used. If the exchange occurs over HTTPS, you’ll get info about the SSL handshake, the certificates used in the exchange, and other helpful information. The Community ID field, found in NIDS like Suricata and in Zeek, can help pair NIDS alerts with Zeek logs, and Corelight has the added benefit of linking Zeek and Suricata logs together even more tightly through the use of a unique ID that reduces the number of pivots that an IR analyst or threat hunter needs to perform in order to get to the meat of an investigation.
Increased proliferation of security automation and SOAR platforms also provides an opportunity for organizations to see increased value from their IDS and broader network visibility investments. SOAR platforms are extremely effective at automating the initial evidence gathering process to speed up SOC workflows. For example, a team could build automations that trigger on an IDS alert, and run a variety of queries against Zeek-generated data to capture all of the critical pieces of information that a SOC analyst would use to rapidly evaluate whether an alert was ignorable or whether it required further investigation by more senior threat investigators. The combination of SOAR, IDS, and NTA can produce incredible security outcomes, and at Corelight, we’re working to make that easier with off-the-shelf playbooks.
The pairing of Zeek with a NIDS like Suricata serves dual purposes:
Enrichment with CMDB data produces well-contextualized alerts
One of the biggest questions when an alert fires is: “how bad is this?” Contextualization is everything when securing a network, and analysts spend a huge amount of time attempting to make the connection between an IP or hostname to an understanding of the criticality of the asset. A high-severity alert firing on a low-priority asset might be less concerning than a low-severity alert firing within an extremely high-priority enclave. Frequently, the fastest way to understand the importance of an alert is with metadata from a configuration management database (CMDB) like ServiceNow.
This is another place where Zeek integrations with NIDS can become extremely valuable. Zeek provides a module called the Input Framework, which can be used to load in external information that is used to automatically enrich network events. For example, you could use the Input Framework to pull in data from a CMDB to map subnets to human-readable labels, or map from hostnames or IPs to the sensitivity of the asset (like if there is employee information or financial or health-related data stored on the asset). It may be a SOC’s policy that any alert within a particular enclave requires additional investigation, but without appropriate tagging and labeling, the exercise of determining severity becomes that much harder. This isn’t a perfect silver bullet, as asset inventories and CMDBs often end up outdated and stale, but more visibility is generally better than less. This also provides an opportunity to leverage NTA and IDS systems to identify gaps in a network inventory, and opens the possibility of a feedback loop to close those gaps, which, in turn, improves incident response capabilities.
Making efforts to know your network is key to security success
It’s important to recognize that the value of a NIDS is very directly correlated to the effort that is put into tuning, curating, and crafting a ruleset, but that the time and energy will be rewarded in spades. By pairing NIDS with systems like CMDBs, vulnerability scanners, and NTA tools like Zeek, security organizations can produce feedback loops and flywheels that enable greater understanding of their own networks. Many security practitioners would laugh if you asked them how well they understand what’s on their network. Networks are often highly opaque, hosts are transient, and can be difficult to understand. However, by making the effort to better understand your network, a NIDS investment can go from a sunk cost to producing extreme value.