Zeek
Mission First, People Always.
I’m Amber Graner, and I’m excited to join Corelight, Inc as the Director of Community for the open source Zeek project.
The past few weeks have seen several developments around Community ID, our open standard for rendering network traffic flow tuples into a concise textual representation. I’d like to summarize them in this blog post.
We introduced Community ID in 2018 to simplify the correlation of network traffic logs across different monitoring applications. For example, let’s say you need to query your logs for all TCP traffic between 2607:f8b0:400c:c03::1a’s port 2345 and 2001:470:e5bf:dead:4956:2174:e82c:4887’s port 443. It is much more difficult to extract this flow tuple reliably from a range of different log formats, and then to match it reliably, than to tag your logs records with Community IDs and simply search everything for the resulting tag, which in this case is “1:RXd76pOsi7yyeZ2PEv0Udb8vEXs=”.
Suricata and Zeek gained Community ID support early on, and over the past two years the NDR community has expanded support to a range of systems, languages, and platforms. (You can see that list grow here — let us know if we missed anything!) Last week another important application added Community ID support: Wireshark, with its 3.3.1 development release. Let me show you this new functionality.
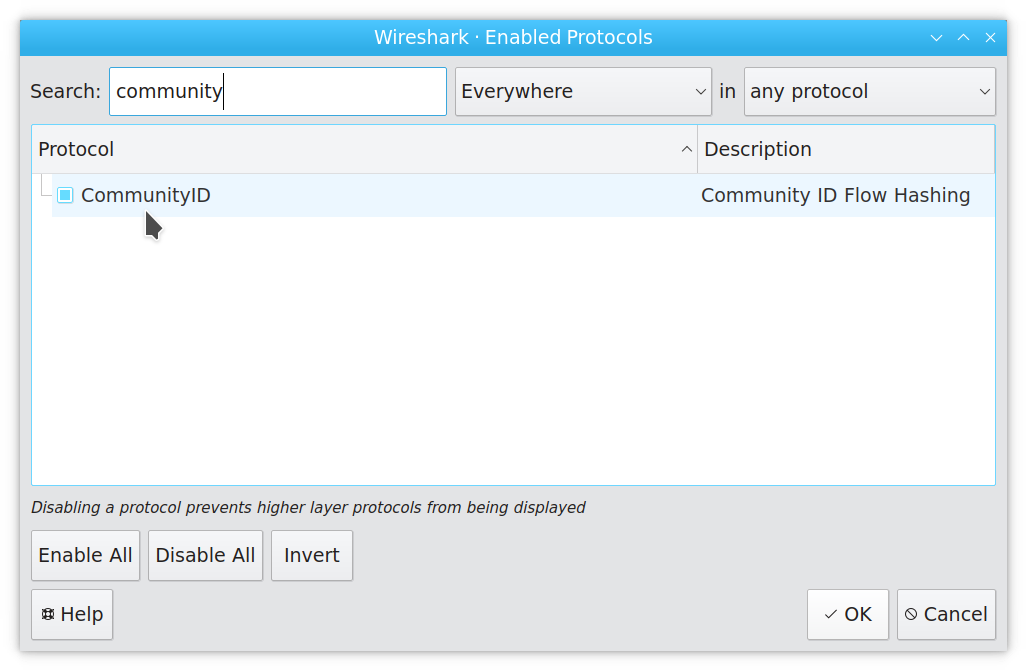
The goal of Wireshark’s Community ID support is to display the ID tags right as you browse packets. By default the Community ID dissector is disabled, so let’s enable it: select “Analyze” ➝ “Enabled Protocols…” and in the resulting dialog find Community ID in the list of protocols. Enable it, and hit OK:
In the packet details pane you’ll now see the Community ID tag for the currently viewed packet rendered at the bottom of the protocol tree:

Wireshark adds square brackets to indicate that the tag is a “generated field”, meaning that it doesn’t contain an on-the-wire protocol field but a value derived from other fields.
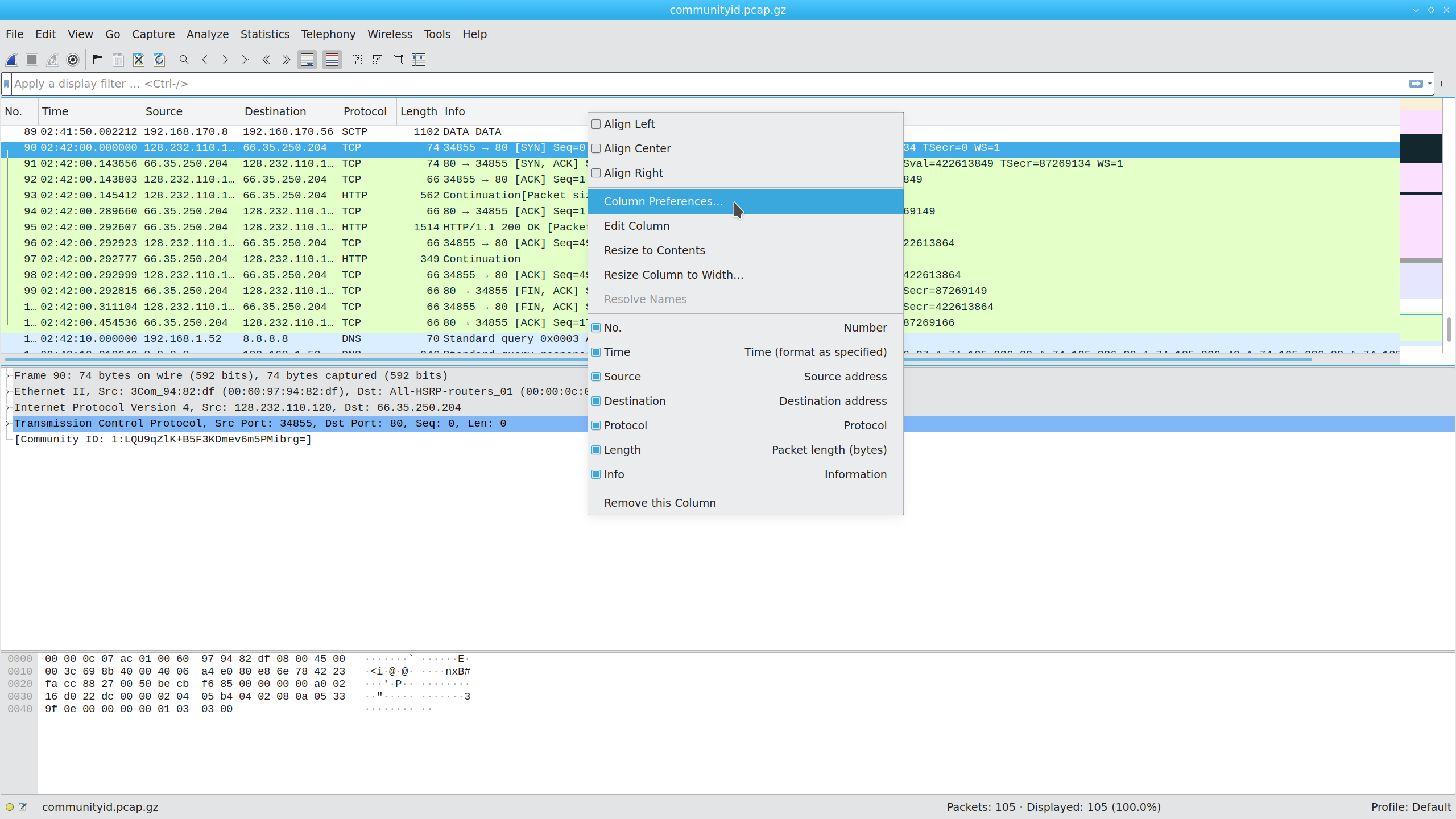
If you regularly rely on Community ID tags, you might prefer to see them directly in the packet list, so let’s add a column. Start by right-clicking a column header, then select “Column Preferences …” from the pop-up menu:
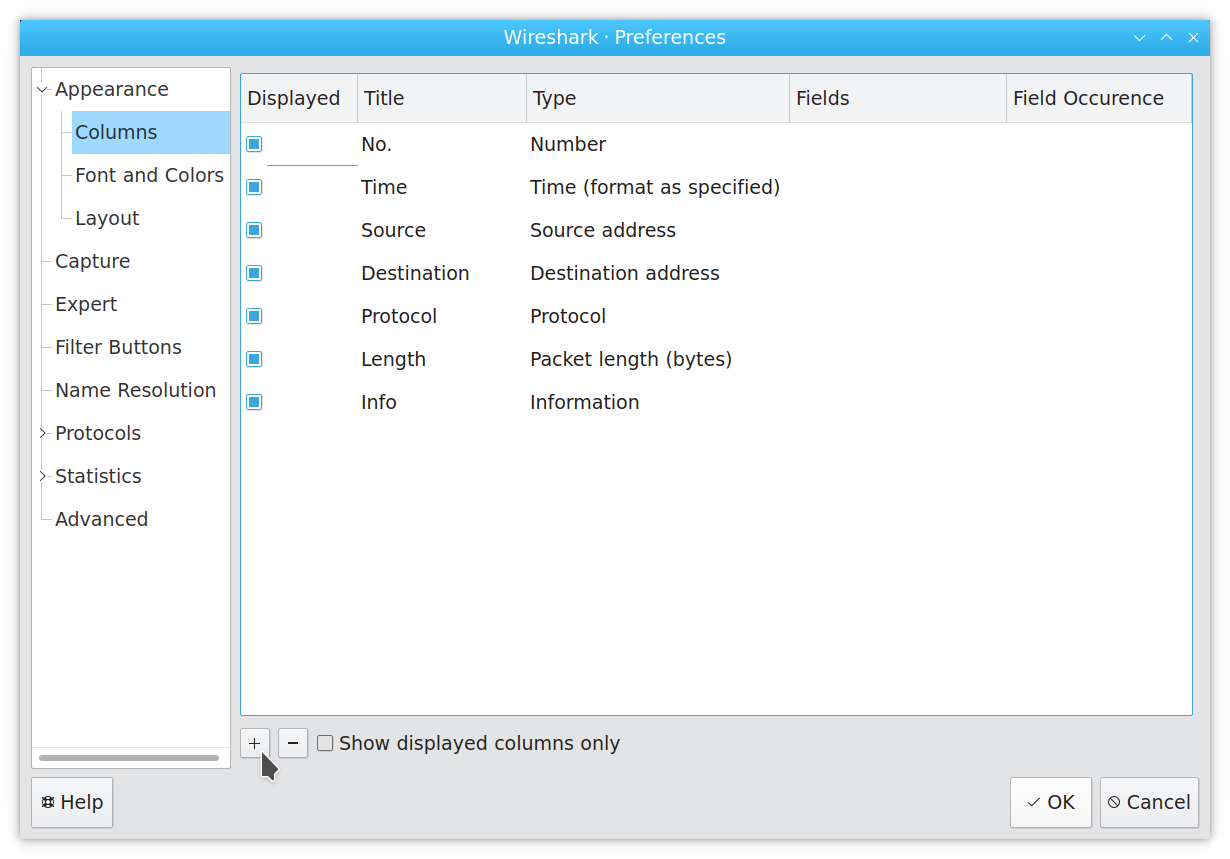
In the resulting dialog, click “+” to add a new column:
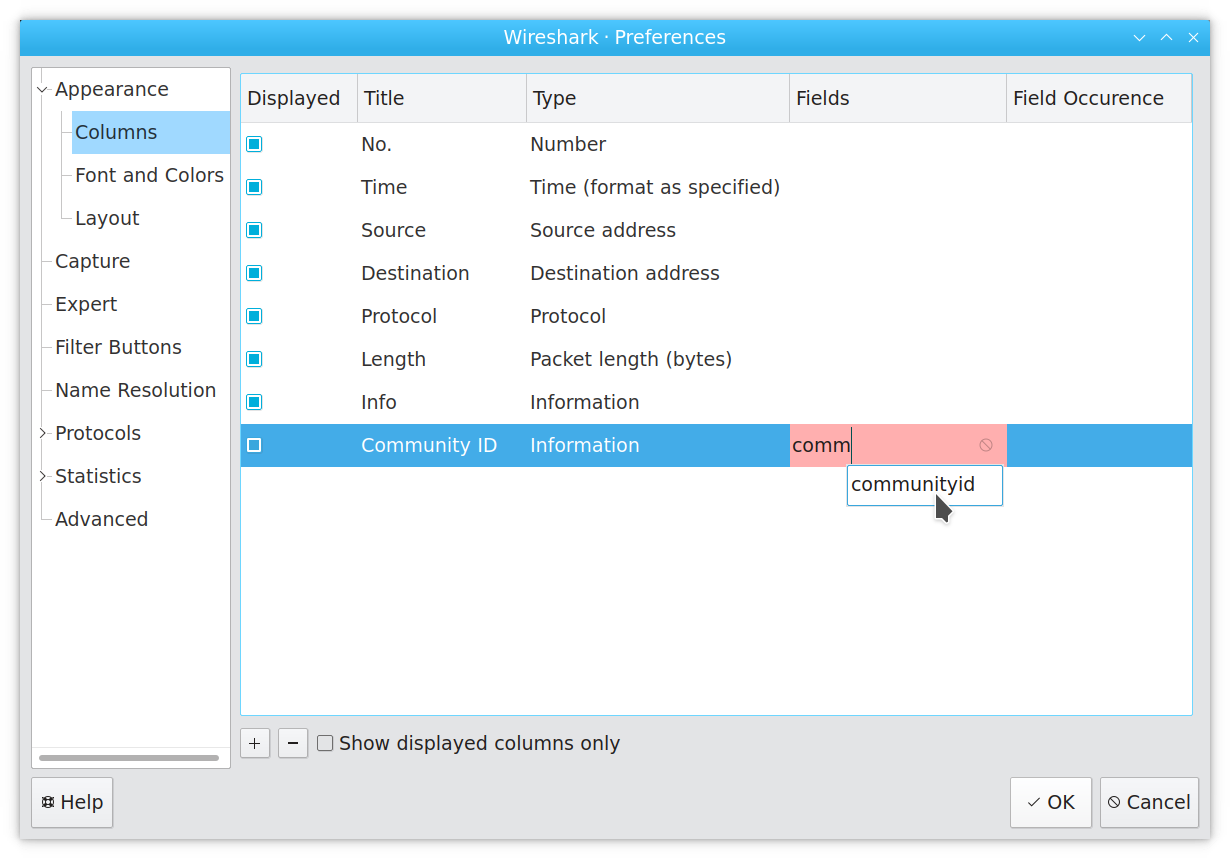
Enter “Community ID” for the title, select “Information” for the column type, and filter the “Fields” search box down to the communityid field:
Click OK, and your new column is now visible:

If you don’t immediately see the column, Wireshark probably just rendered it off-screen to the right. A horizontal scrollbar on the packet list is a good indicator. Adjust the column widths as needed.
The communityid field also works in the filter language, so you can now filter pcaps by Community ID tag:

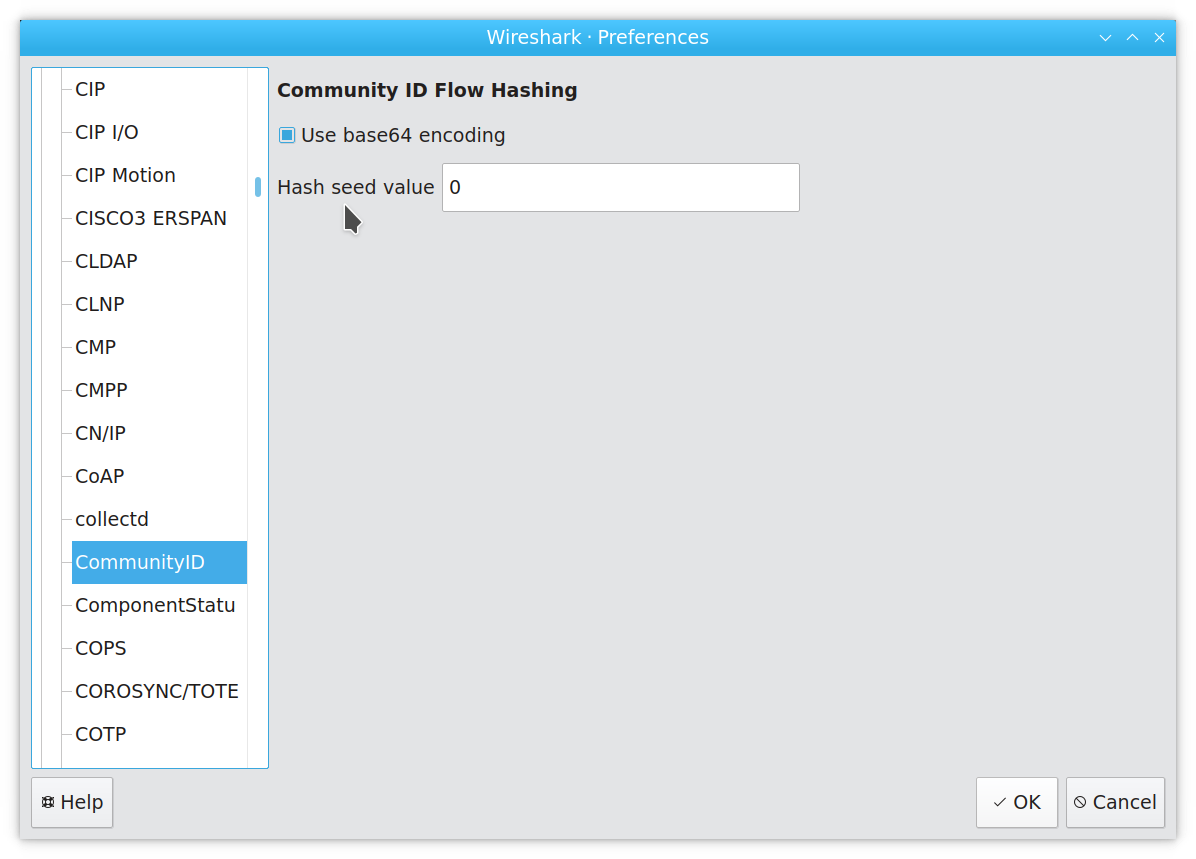
If you customize your Community ID computations, you can do this in Wireshark as well. Click “Edit” ➝ “Preferences”, and find the Community ID entry in the protocol list:
For me Wireshark comes in really handy on occasion, but in practice I use its textual cousin, tshark, much more often. Since tshark automatically features the same dissectors as Wireshark, you can now check Community ID values wherever you use tshark. If you have Community ID enabled and added a column for it, you’ll automatically see Community ID tags when using tshark to dump traffic, and you can filter just as in the GUI:

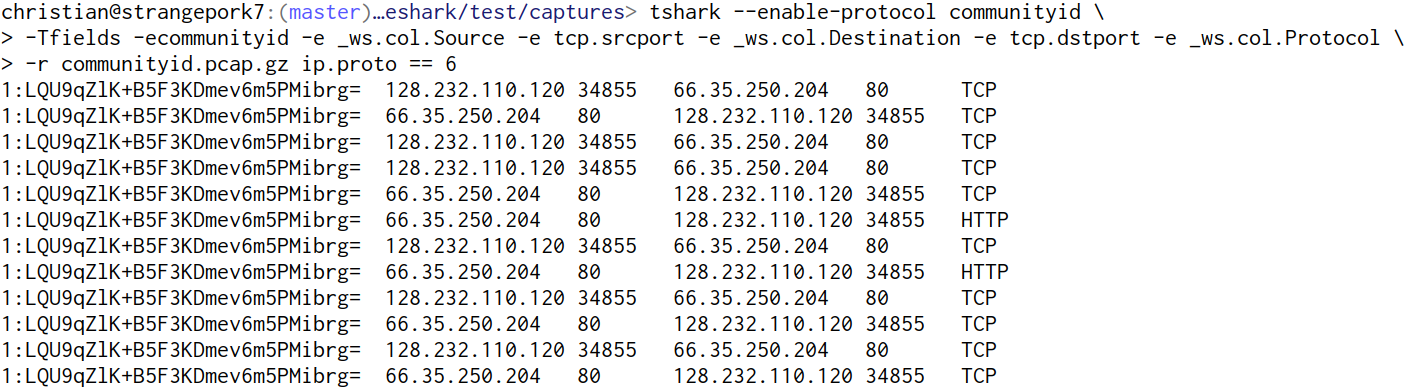
Without Wireshark’s configuration you can always enable the analyzer via a command-line flag and spell out columns explicitly, as in this example:
As part of this work we also released a simple C implementation of Community ID that Wireshark’s support is based on. The Python package now supports additional variations of input flow tuples, features JSON output for tuples and tags, and relies on a better test suite. Finally, the spec’s main repository now has reference data to make it easier to check whether your implementation reports correct values.
If you’re using Community ID in production, we’d love to hear from you, particularly regarding any features to include in a v2, which we’re starting to think about. If you’ve added support for it to any systems, thank you! Please send us a pointer, and we’ll make sure to add it to the list.